Ab Testing Mistakes I Learned the Hard Way
A/B testing mistakes I learned the hard way #
Excerpt #
Bad experiments are worse than none at all
Welcome to Product for Engineers, a newsletter created by PostHog for engineers and founders who want to build successful startups.
Running experiments is equal parts powerful and terrifying.
Powerful because you can validate changes that will transform your product for the better; terrifying because there are so many ways to mess them up.
I’ve run hundreds of A/B tests, both in my previous life as a growth engineer at Meta, and on my personal side project.
These are some classic mistakes I’ve learned the hard way and how to avoid them.
1. Testing an unclear hypothesis #
A good hypothesis explains both what you’re testing and why you’re testing it. A bad one will just lead to a lot of wasted time, or worse still changes that unknowingly damage your product.
To understand this better, let’s look at a classic example of a bad hypothesis:
❌ Bad hypothesis: Changing the color of the “Proceed to checkout” button will increase purchases.
It’s bad because it’s unclear both why we’re testing this change and why we expect it to increase purchases.
As a result, we’re unsure what we need to measure. Do we only need to count button clicks, or are there other metrics we need to look at?
Here’s a better version:
✅ Good hypothesis: User research showed that people are unsure of how to proceed to the checkout page. Changing the button’s color will lead to more people noticing it and proceeding to the checkout page. This will lead to more purchases.
It’s clear now what we need to measure both:
Button clicks, to see if changing the color leads to more people noticing the checkout button.
Number of purchases, since more people arriving at the checkout page should mean more purchases.
This also makes it easier to investigate the results when they’re not what we expect:
If button clicks stay the same, the page may have a different problem.
If button clicks increase but the number of purchases do not, there may be an issue with the checkout page.
Avoid this by… #
Ensuring your hypothesis answers these three questions:
Why am I running the test?
What change am I testing?
What do I expect to happen?
2. Only viewing results in aggregate #
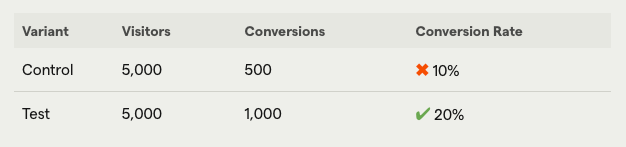
Imagine you’re testing a change to your sign-up flow and you run the test on 1,000 users.
The change affects both desktop and mobile users and you get the following results:
[

{kind=link}
This looks like a clear win for the new version, but breaking down the results by device-type shows something completely different:
[

{kind=link}
In fact, while the new flow worked great on mobile, conversion was lower on desktop – an insight we missed when we combined these metrics.
This phenomenon is known as Simpson’s paradox – i.e. when experiments show one outcome when analyzed at an aggregated level, but a different one when analyzed by subgroups.
Avoid this by… #
Breaking down your experiments by relevant user properties, like:
User location or language
Subscription or pricing tier
New vs existing users
Device type
Business size
Job title or category
Acquisition channel
3. Including unaffected users in your experiment #
This means including users who don’t have access to the feature you’re testing, or have already completed the goal of your test – e.g. running a pricing experiment, but including users who have already subscribed to your product.
Including these unaffected users will skew results, either leading to incorrect conclusions, inconclusive results, and/or longer experiment durations because there are too many “idle” users in an experiment’s test group.
Avoid this by… #
Filtering out ineligible users in your code before you evaluate their experiment variant**.**
These code blocks assume you’re using PostHog for A/B testing, but the principles apply to any tool you’re using.
<span>❌ Wrong
function showNewChanges(user) {
</span><strong>if (posthog.getFeatureFlag('experiment-key')</strong><span> === 'control') {
return false;
}
</span><strong>if (user.hasCompletedAction) {</strong><span>
return false
}
// other checks
return true
}
</span>
The above is wrong because posthog.getFeatureFlag is called before the if (user.hasCompletedAction) check.
<span>✅ Correct
function showNewChanges(user) {
</span><strong>if (user.hasCompletedAction) {</strong><span>
return false
}
// other checks
</span><strong>if (posthog.getFeatureFlag('experiment-key')</strong><span> === 'control') {
return false;
}
return true
}</span>
This code will filter out those users before including them in the experiment.
4. Ending tests too early… #
… aka The Peeking Problem.
Sure, you might want to see how your test is performing before it’s finished, but don’t make decisions using incomplete data.
Be especially wary if the early results are statistically significant, since this may actually change in the final results. As Airbnb found, it’s possible for tests to hit “significance” early in an experiment’s running, only to converge back to neutral.
Don’t fall victim to temptation.
Avoid this by… #
Calculating how long you need to run your A/B test before you start and sticking to it. Without it, you can’t differentiate between intermediate or final results.
We calculate the recommended test duration automatically in PostHog, but you can do it manually using any number of online calculators provided you have the following:
The current count or conversion rate for your metric.
Your “minimum detectable effect” – the smallest change you want to detect.
Your desired level of confidence. The industry standard is 95%.
5. Running an experiment without testing it first #
Sometimes engineers are so eager to get results from their experiments that they jump straight to running them with all their users.
This might be okay if everything is set up correctly, but if you’ve made a mistake, you may be unable to rerun your experiment.
Imagine you start an A/B test with all your users, but a few days later you notice that your change is causing the app to crash for many users. You immediately stop the experiment and fix the root cause of the crash.
Restarting the experiment now will produce biased results since many users have already seen your change.
Avoid this by… #
Heeding the sage advice Ice Cube: “Check yourself before you wreck yourself.”
Run a phased rollout with a small group of users for a few days. Once you’re confident everything works correctly, you can start the experiment with the remaining users.
Here’s a list of what to check during your rollout:
Logging is working correctly.
No increase in crashes or other errors.
Session replays to ensure your app is behaving as expected.
Users are assigned to the control and test groups in the ratio you are expecting (e.g. 50/50).
6. Neglecting counter metrics #
Counter metrics are vital metrics that could be indirectly impacted by your experiment. They can reveal unintended negative side-effects that harm your product or business.
For example, say you’re testing a change to your signup page. Conversion increases, indicating the change is working, but you also see a drop in activation, and little discernible increase in daily active users.
These are counter metrics and they’re suggesting your change is leading to more new users who don’t onboard or use the product. This could be because the new page is misleading users about what your app does, resulting in more signups but also more churn.
Avoid this by… #
Creating a list of product health metrics you want to monitor, such as retention, session duration, or daily active users, and check how they change during and after your experiment.
Another option is to run a holdout test, where a small group of users is not shown your changes for a long period of time – e.g. weeks or months after your experiment ends. This helps you to verify that the experiment doesn’t have negative long-term effects.
Good reads 📖 #
We’ve decided to make less money [Part 1] and [Part 2] – We recently decided to massively cut pricing for both our session replay and analytics products. These posts cover how and why.
Why perfectionism destroys your productivity, and what to do instead –
and share how to fight the urge to over polish your work, and discover the magic of “good enough”.
Statistical Significance on a Shoestring Budget – Alexey shares techniques on how to increase experimental power when you’re lacking user volume.
A software engineer’s guide to A/B testing – This guide I wrote for the PostHog blog covers common misconceptions about A/B testing, and how to approach running your first ever A/B test.
Words by Lior Neu-ner, who has wasted months of his life running pointless A/B tests.
Subscribe to Product for Engineers #
Helping engineers and founders flex their product muscles