Most Used Distributed System Design Patterns by Anil Gudigar Javarevisited Jun, 2024 Medium
Most-Used Distributed System Design Patterns | by Anil Gudigar | Javarevisited | Jun, 2024 | Medium #
Excerpt #
Distributed system design patterns provide architects and developers with proven solutions and best practices for designing and implementing distributed applications. These patterns encapsulate…
[

]( https://medium.com/@anil-gudigar?source=post_page-----d5d90ffedf33--------------------------------)[

]( https://medium.com/javarevisited?source=post_page-----d5d90ffedf33--------------------------------)
Distributed system design patterns provide architects and developers with proven solutions and best practices for designing and implementing distributed applications.
These patterns encapsulate decades of collective experience and are instrumental in addressing the complexity of distributed computing.
Some of the most widely used distributed system patterns include:
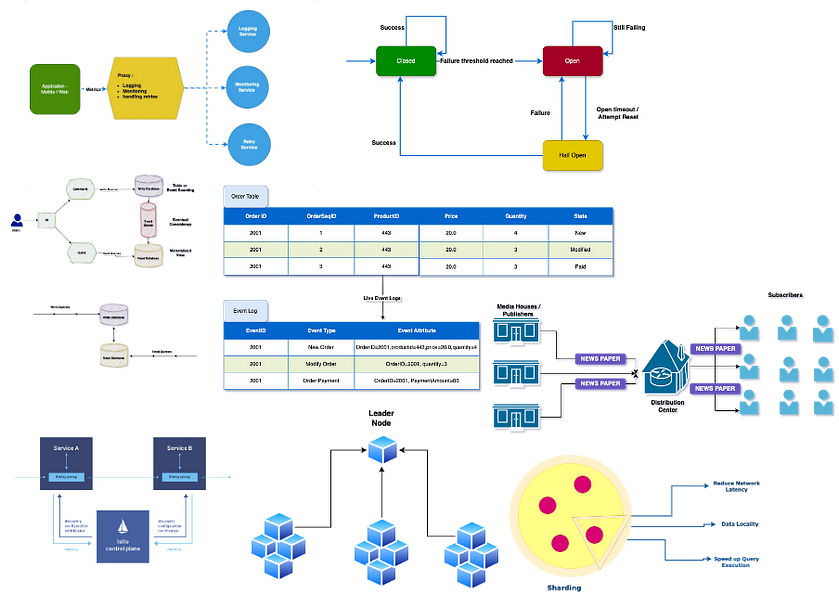
Ambassador — Proxy #
The ambassador pattern focuses on offloading all the major tasks that are critical to applications other than business logic so that applications can focus only on critical use cases.
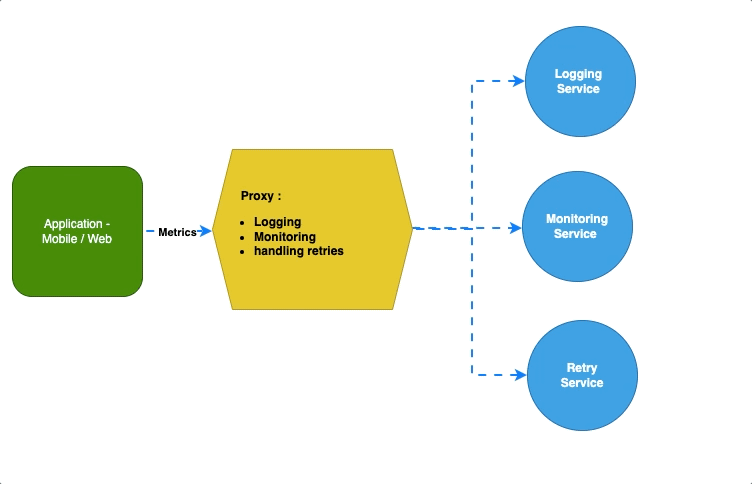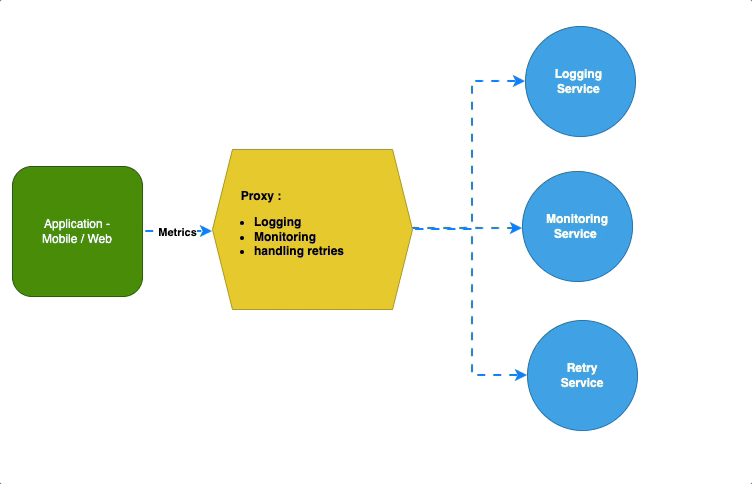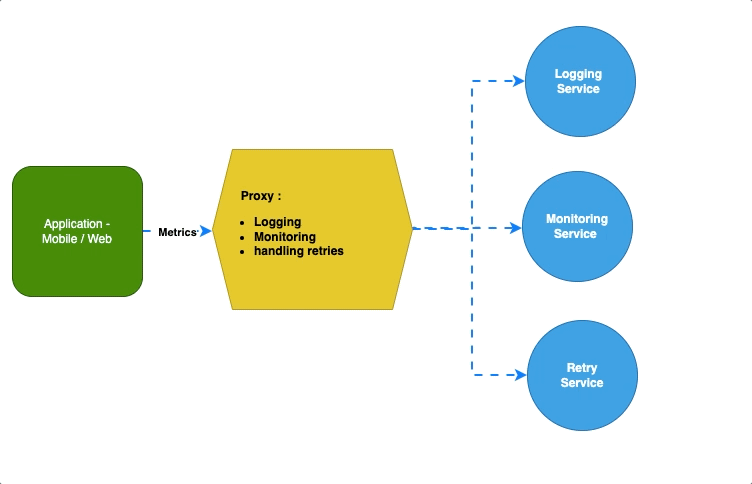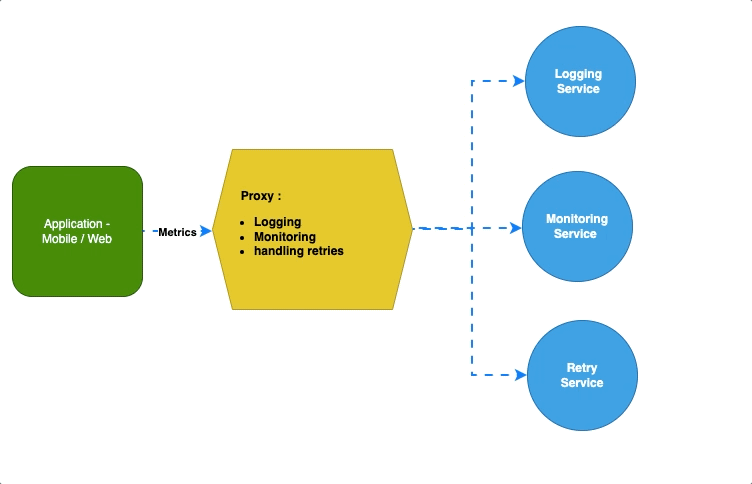
It acts as a “go-between” for applications and the services it communicates with, offloading tasks like logging, monitoring or handling retries, and rate limiting.
For Example, K8 uses Envoy as an ambassador to simply communicate between services.
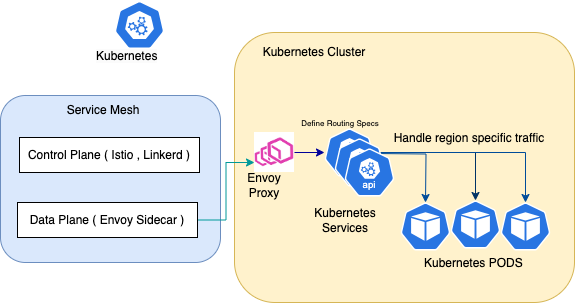
Envoy Gateway and Service Mesh
Istio provides numerous features that make software development and delivery faster, easier, and more secure. #
Security: Istio helps application teams achieve zero trust security with the ability to define and implement authentication, authorization, and access control policies.
Service Discovery: One of the primary needs of an application running in a production environment is to be highly available. This requires one to scale up the number of service instances with increasing load and scale down when needed to save costs. Istio’s service discovery capability keeps track of all the available nodes ready to pick up new tasks. In case of node unavailability, service discovery removes a node from the list of available nodes and stops sending new requests to the node.
Traffic Management: Using Envoy proxies, Istio provides flexibility to finely control the traffic among the available services. Istio provides features like load balancing, health checks, and deployment strategies. Istio allows load balancing based on algorithms that include round-robin, random selection, weighted algorithms, etc. Istio performs constant health checks of service instances to ensure they are available before routing the traffic request. Based on the deployment type used in the configuration, Istio drives traffic to new nodes in a weighted pattern.
Resilience: Istio removes the need for coding circuit breakers within an application. Istio helps platform architects define mechanisms such as timeouts to a service, the number of retries to be made and planned automatic failover of high availability (HA) systems, without the application knowing about them.
Observability: Istio keeps track of network requests and traces each call across multiple services. Istio provides the telemetry (such as latency, saturation, traffic health, and errors) that helps SREs understand service behaviour and troubleshoot, maintain, and optimize their applications.
Circuit Breaker #
Imagine a water pipe breaks down the house, the first thing we should do is shut down the main valve to prevent further damage. the circuit breaker pattern works similarly preventing cascading failures in distributed systems.
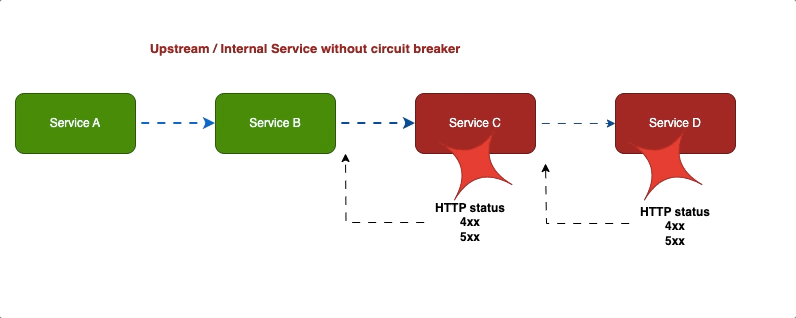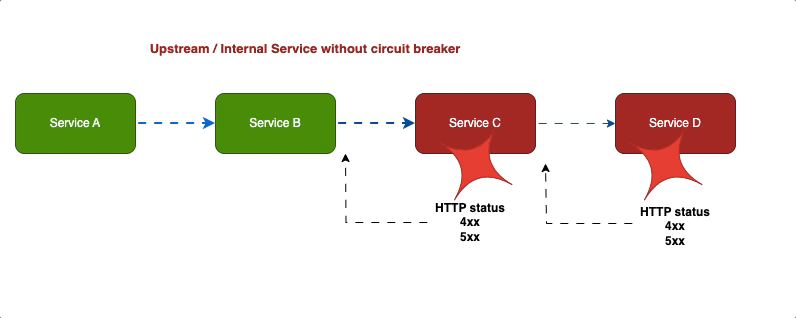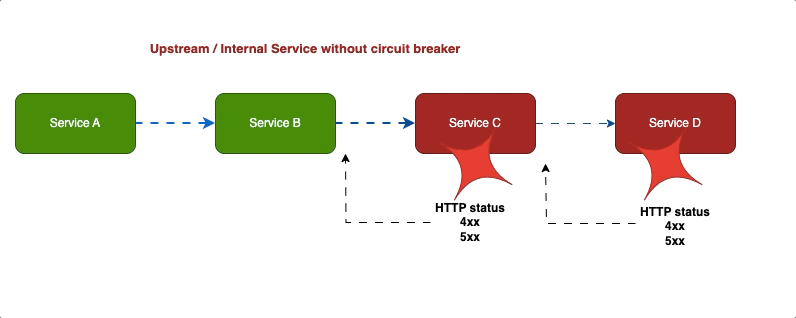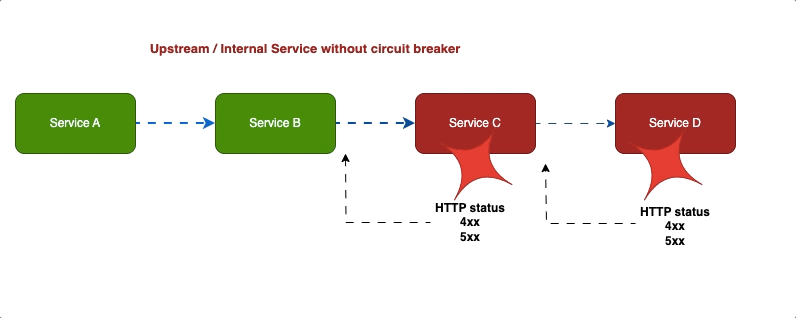
Service cascade failures with out circuit breaker
When service becomes unavailable, the circuit breaker stops requests, allowing it to recover, we use circuit breaker patters to prevent further damage.
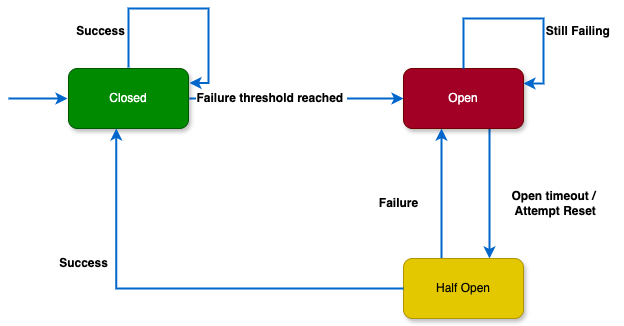
Circuit Breaker Pattern
Closed:
In this state, the circuit breaker allows normal service communication, and requests go through to the service.
Circuit breaker monitors the responses from the service for errors ( 4XX , 5XX HTTP Code ). If the responses are successful ( 200 OK ) with no issues, it remains in the closed state.Open:
When the number of failures reaches a threshold, the circuit breaker switches to the open state (4XX , 5XX HTTP Code with some threshold count < 30 ), preventing requests from reaching the service and providing a fallback response.
(Threshold Value like 30 failures within 10 seconds)Half-Open:
Once the timeout or reset interval passes, the circuit breaker goes to the “Half-Open” state.
It allows a limited number of test requests to pass through to the service to see if the service has recovered or not.
If the test requests succeed ( 200 OK ) , it means the service has recovered and the circuit breaker goes back to “Closed” state.
If any of the test requests fails, it means the service has still issues and the circuit breaker goes to “Open” state to block further requests.
There are several tools and frameworks implementing the circuit breaker pattern. Here are some popular options:
- Netflix Hystrix:
Hystrix is an open-source Java library that provides an implementation of the circuit breaker pattern to handle faults tolerance and latency in distributed systems and micro services architectures.
Note: Netflix has officially entered maintenance mode, and users are switching to use alternatives like resilience4j or Sentinel.
Key features of Resilience4j include:
Retry: It allows you to define retry strategies for failed operations, and specify how many times an operation should be retried.
Rate Limiter: This allows you to control the traffic to some parts of your application by limit the rate of requests to a service to prevent overloading them.
Fallback: It allows you to define fallback functions or responses when an operation fails and gracefully shut down and improve user experience.
2. Resilience4j:
Resilience4j is a lightweight, easy-to-use library, which offers a powerful circuit breaker implementation inspired by Netflix Hystrix but designed with functional programming approach.
3.Istio:
Istio is a service mesh platform that helps you manage traffic between micro services. It provides a number of features, including:
Circuit breaker: A fault tolerance pattern that can route traffic away from unhealthy micro services and automatically retry failed requests.
4.Sentinel:
It is an open-source library that provides monitoring of services and controls the traffic.
It can be used to implement circuit breaking, rate limiting.
Sentinel can work in both Java and other languages.
5.Amazon App Mesh:
Amazon App Mesh is a managed service mesh that allows you to monitor and control services running on AWS.
It provides features like circuit breaking, retries, and more to enhance the reliability of your micro services.
CQRS (Command Query Responsibility Segregation) #
CQRS separates reads and writes into different databases, Commands performs update data, Queries performs read data.
An E-Commerce platform might have high read requests for products listing but fewer writes requests for placing orders.
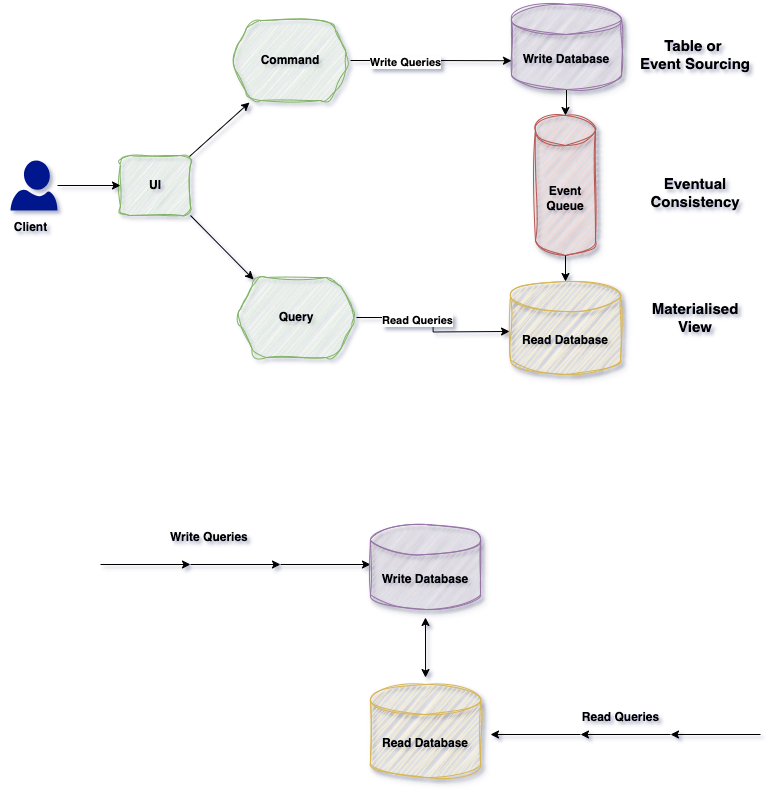
CQRS design pattern
In monolithic applications, a single database typically handles both query and update operations, managing complex joins and CRUD tasks. As applications grow more complex, these operations can become unmanageable.
For example, a query requiring joins across more than 10 tables can lock the database due to latency, while CRUD operations with complex validations can also cause locks.
To address this, CQRS separates read and write operations into different databases, applying the “separation of concerns” principle. This allows using, for instance, a NoSQL database for read operations and a relational database for writes.
Understanding the application’s behavior is crucial. If the application is read-heavy ( understand Read : Write ratio non functional requirement), the architecture should prioritize optimizing read operations.
In an Example of E-Commerce Application: #
Commands should be actions with task-based operations like “add item into shopping cart” or “checkout order”. So commands can be handle with message broker systems that provide to process commands in async way.
Queries is never modify the database. Queries always return the JSON data with DTO objects. By this way, we can isolate the Commands and Queries.
In order isolate Commands and Queries, its best practices to separate read and write database with 2 database physically. By this way, if our application is read-intensive that means reading more than writing, we can define custom data schema to optimized for queries.
Materialized view pattern is good example to implement reading databases. Because by this way we can avoid complex joins and mappings with pre defined fine-grained data for query operations.
By this isolation, we can even use different database for reading and writing database types like using no-sql document database for reading and using relational database for crud operations.
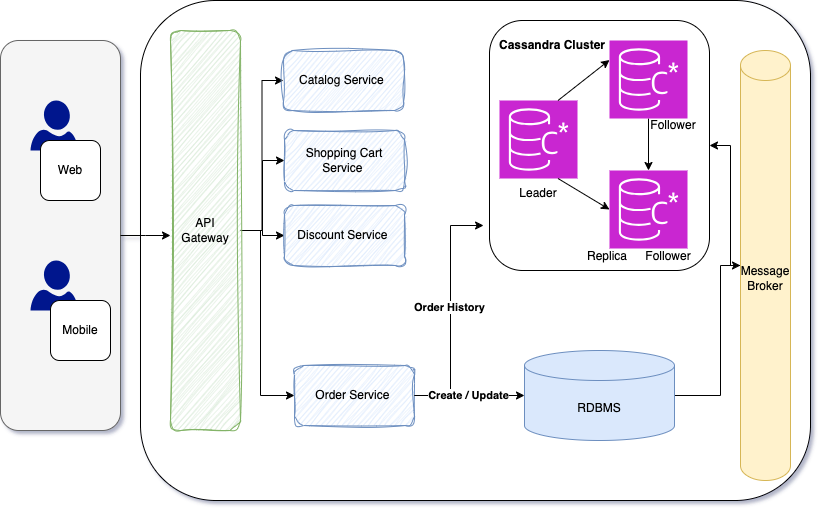
Now we can design our Ordering microservices databases
Split 2 databases for Ordering microservices
1 for the write database for relational concerns
2 for the read database for querying concerns
So when user create or update an order, I am going to use relational write database, and when user query order or order history, I am going to use no-sql read database. and make consistent them when syncing 2 databases with using message broker system with applying publish/subscribe pattern.
Now we can consider tech stack of these databases,
SQL Server ( PostgreSQL / MySQL**)** for relational writing database, and using Cassandra for no-sql read database. Of course we will use Kafka for syncing these 2 database with pub/sub Kafka topic exchanges.
Event Sourcing #
Think of event sourcing as keeping a journal of the live events.Instead of storing the current state of data, this pattern records a sequence of events that led to the current state.
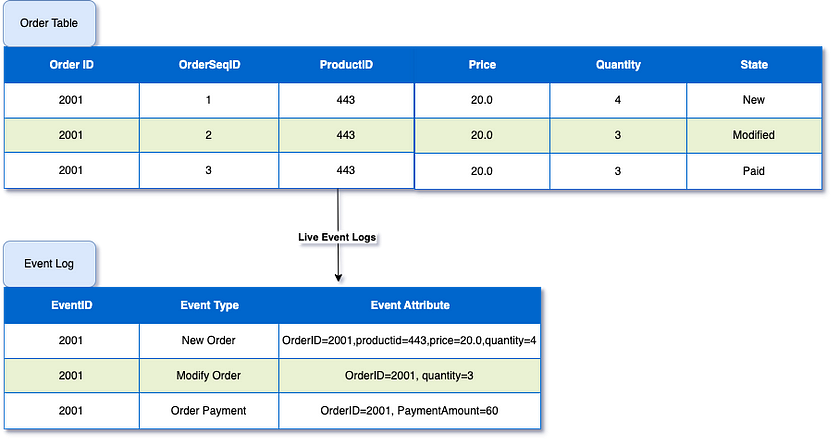
Event Sourcing
Benefits: Provides a complete audit trail, enables complex event processing, and improves consistency. with event sourcing we can also implement time travel debugging or replaying events for analytics purposes.
Challenges: Requires careful design of event schemas and handling event replay for rebuilding state.
Sidecar Pattern #
Deploys auxiliary components (sidecars) alongside the main service containers to manage cross-cutting concerns like logging, monitoring, and configuration.

The Sidecar concept in Kubernetes is becoming popular. Containers should focus on a single concern and do it well, and the Sidecar pattern supports this by separating core business logic from additional tasks.
This pattern involves two containers on a single node. The first is the primary application container with the core logic, and the second is the Sidecar container, which enhances the primary application by running in parallel within the same Pod. They share resources like the filesystem, disk, and network.
The Sidecar pattern also allows deploying different components of the same application in isolated containers, which is beneficial for sharing common components across a micro service architecture, such as logging, monitoring, and configuration properties.
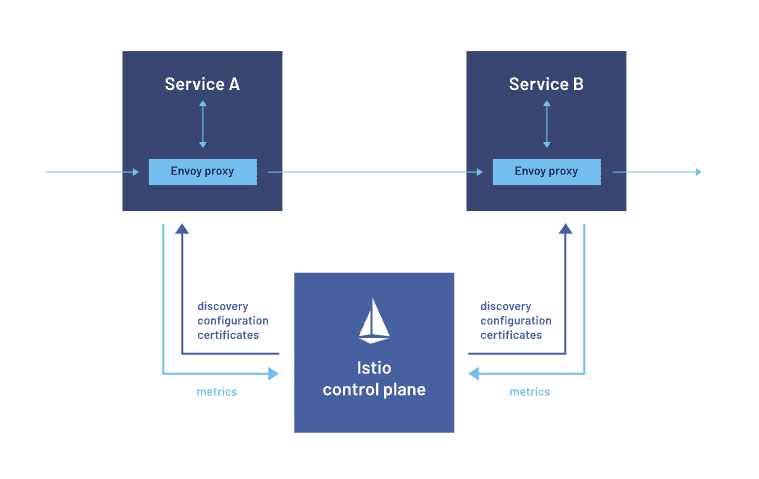
Istio Sidecar
Benefits: Enhances modularity and maintainability.
Examples: Istio for service mesh, Envoy as a sidecar proxy.
Leader Selection #
In distributed systems, some tasks need a single leader. Leader election algorithms ensure one node is designated as the leader.
In this pattern it ensure that only one node is responsible for a specific task or resource.
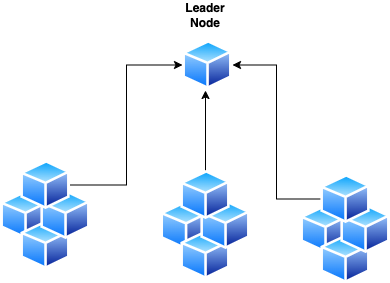
If Leader node Fails the remianing nodes elect a new leader. Zookeeper, etcd. use this patterns to manage distributed configurations.
By having a designated leader, we can avoid conflicts and ensure consistent decision making across the distributed system.
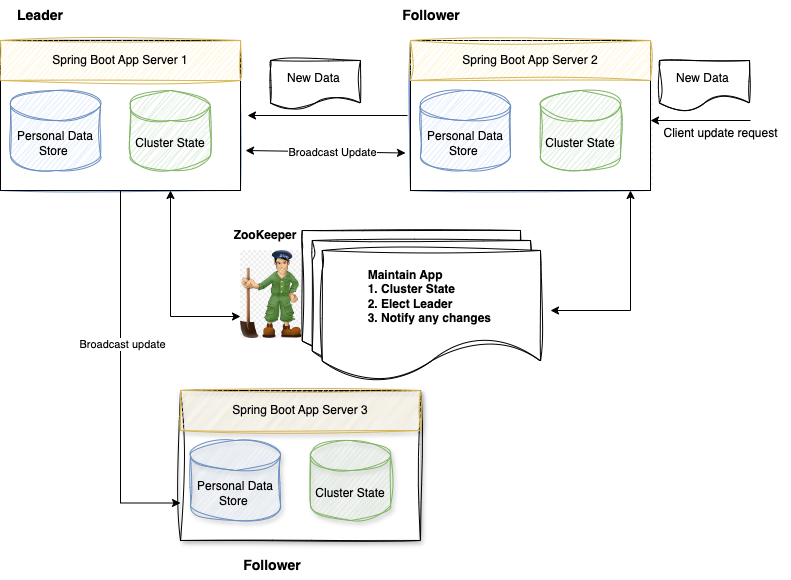
In the above diagram:
- Three Spring boot App server running on port 8081, 8082 and 8083 is used as a database that stores Persona Data.
- Each spring boot server connects to a standalone zookeeper server during startup.
- Each spring boot app server will maintain and store the cluster-info in its memory. This cluster-info will tell current active servers, the current leader of the cluster, and all nodes that are part of this cluster.
- We will create 2 GET APIs, to get info about the cluster and person data and 1 PUT API to save Person data.
- Any Person update request coming to the App server will be sent to Leader and which will broadcast the update request to all live servers/followers.
- Any server coming up after being dead will sync Person data from the leader.
Benefits: Ensures coordinated activities and consistency.
Examples: Zookeeper, etcd.
Publisher/Subscriber #
This pattern allows services to communicate asynchronously. Publishers send messages without knowledge of subscribers, and subscribers receive messages of interest.
For Example The publisher / subscriber pattern is like news paper delivery service, publishers emits events without knowing how many subscriber receive them, and subscriber listen for events they are interested in.
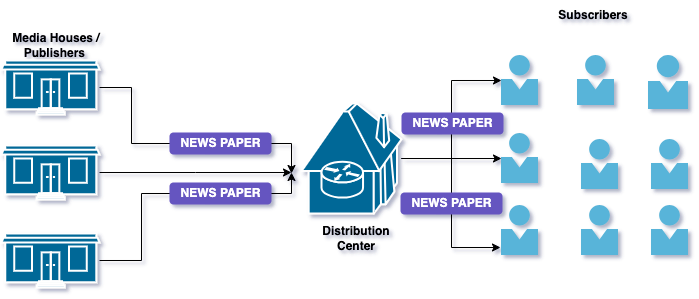
This pattern allows for better scalability and modularity , for example Google Cloud Pub/Sub enables asynchronous messaging between services, making easier to maintain and scale complex applications.
Kafka Event Queue
- The key to this is the fact that Pub/Sub enables the movement of messages between different components of the system without the components being aware of each other’s identity (they are decoupled).
- Pub/Sub provides a framework for exchanging messages between publishers (components that create and send messages) and subscribers (components that receive and consume messages)
Benefits: Decouples message producers and consumers, improves scalability and flexibility.
Examples: Kafka, RabbitMQ, AWS SNS,Google Cloud Pub/Sub.
Sharding #
Divides a dataset into smaller, more manageable pieces (shards) that can be distributed across multiple databases or nodes.
Sharding is like dividing a large pizza into smaller slices, making it easier to handle.
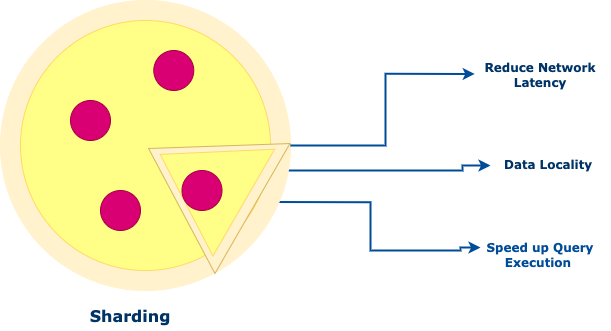
Sharding is technique for distributing data across multiple nodes in a system. It improves performance and scalability.
Each Shard contains a subset of the data, reducing the load on any single node.
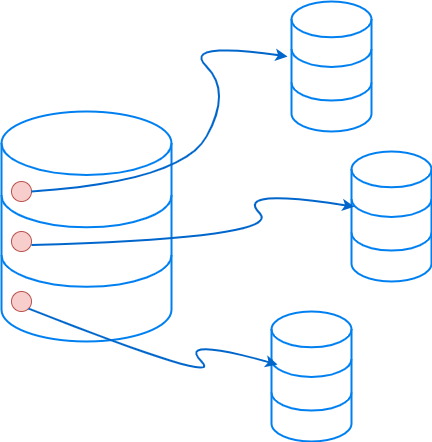
Sharding
Database like MongoDB and Cassandra use sharding to handle large amount of data efficiently.
Sharding can also help is achieve better data locality, reducing network latency and speeding up query execution.
There is significant differences between sharding and partitioning for your reference. We will explain these terms in detail further on.
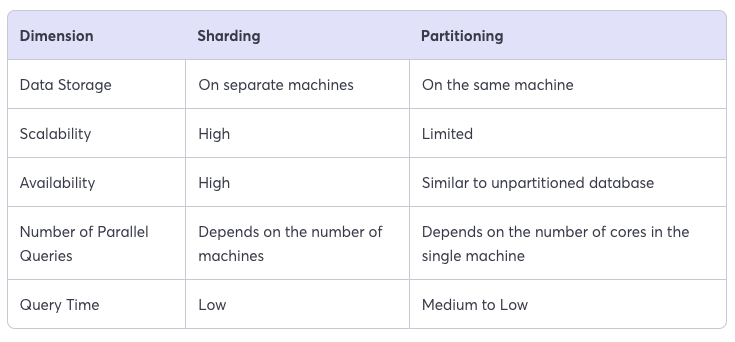
Partitioning #
Partitioning is a general term for splitting a database along a specific axis to produce multiple smaller databases. You can partition a database:
- vertically: i.e., splitting the data, so the smaller databases have the duplicate rows, but different columns
- horizontally: i.e., splitting the data, so the smaller databases have the same columns, or the same schema, but different rows
Sharding #
Sharding is a subset of partitioning. Before we explain sharding and what makes it unique, let’s first examine how data scaling works. As your volume of data increases, you may also need to increase the storage capacity of your database. You could perform vertical scaling (add additional CPU, RAM, storage, etc.) or scale horizontally (add more nodes or machines to your server). We could also describe these choices as either scaling up or scaling out
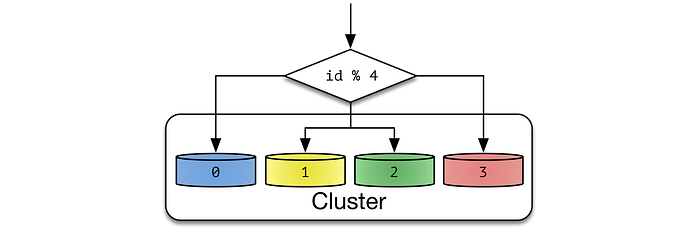
Types of Sharding:
Algorithmic Sharding : In algorithmic sharding, the client can determine a given partition’s database without any help. In dynamic sharding, a separate locator service tracks the partitions amongst the nodes.
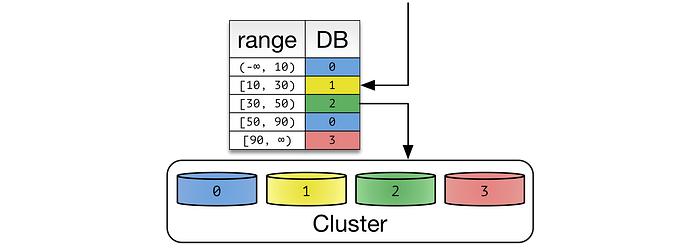
Dynamic Sharding: In dynamic sharding, an external locator service determines the location of entries. It can be implemented in multiple ways. If the cardinality of partition keys is relatively low, the locator can be assigned per individual key. Otherwise, a single locator can address a range of partition keys.
Entity Groups : Store related entities in the same partition to provide additional capabilities within a single partition.
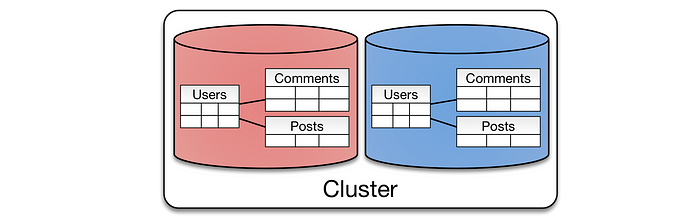
Use cases #
- E-commerce website displaying order / customer / Item information may partition or shard data by country or region, as most queries will retrieve information based on specific locations.
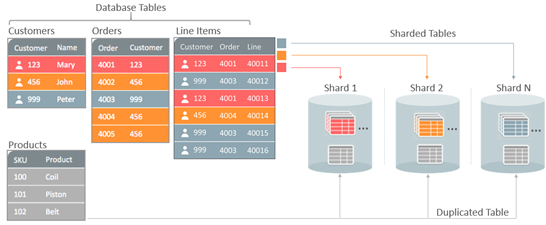
- a stock market analytics firm may partition data by company, or by (company, day) if it wants to perform even granular technical analysis.
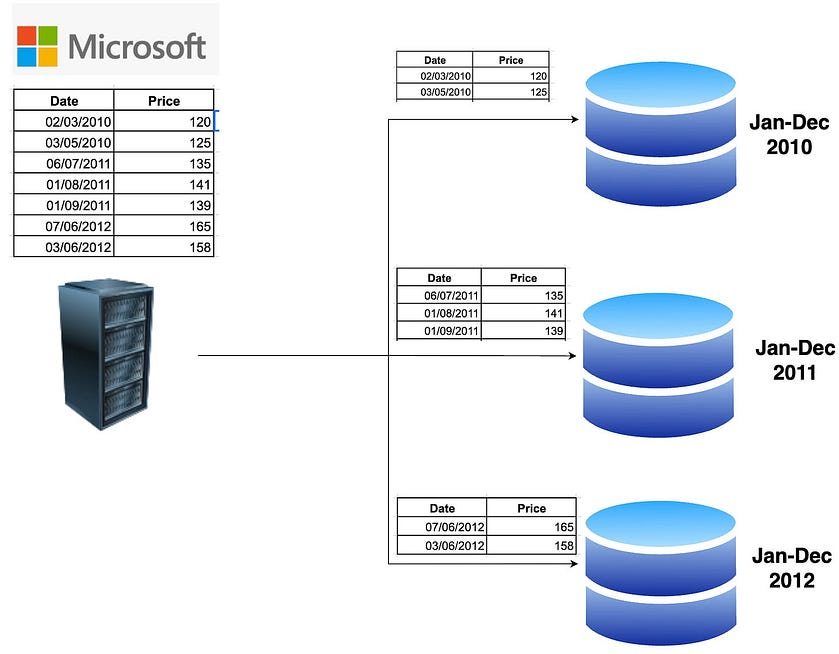
Fetch the stock price between April 2010 till December 2010, we can query Shard 1 and get the data. Additionally, each shard would store the data in a sorted order to improve the query performance. This is illustrated in the below diagram.
Benefits: Enhances scalability and performance.
Challenges: Adds complexity in query routing and managing shards.
Bulkhead #
Isolates components in a system so that a failure in one component does not cause a system-wide failure.
The Bulkhead Pattern is particularly useful in the following scenarios:
- Resource Isolation: When you need to isolate resources used by consumer backend services to prevent resource contention.
- Critical Consumer Isolation: To shield critical consumers (services) from standard consumers, ensuring the availability and responsiveness of critical services even during peak loads or failures.
- Cascading Failure Protection: To safeguard your application from cascading failures that can occur when issues in one service affect others.
Related Patterns:
Bulkhead Pattern can be effectively combined with other cloud design patterns, including:
- Circuit Breaker Pattern: To provide fault tolerance by preventing continuous invocations of a service experiencing issues.
- Retry Pattern: For implementing retry strategies within bulkheads to gracefully handle transient failures.
- Throttling Pattern: To control and limit the rate of incoming requests, preventing a bulkhead from becoming overwhelmed.
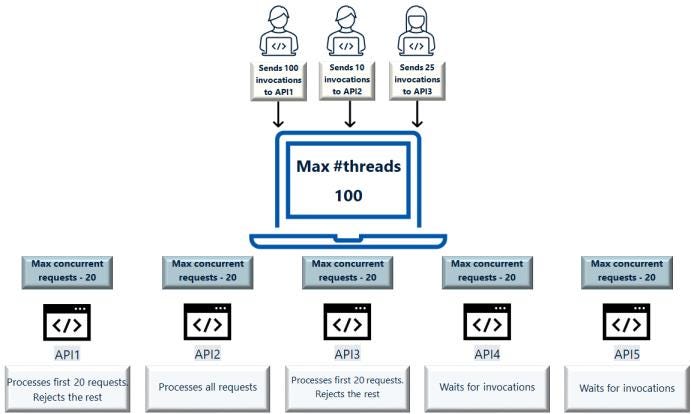
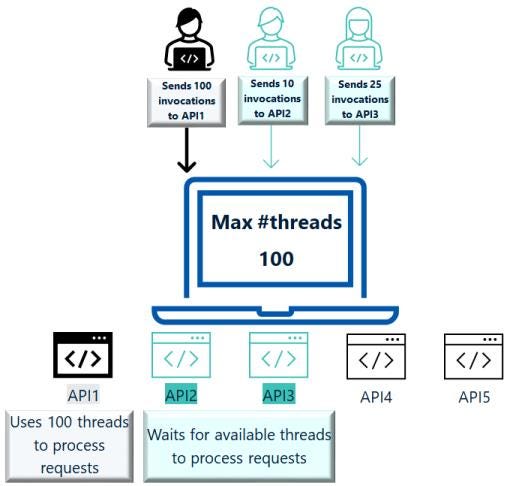
Where we can implement bulkhead ?
Bulkhead configuration in an API gateway allows you to specify the maximum number of concurrent requests that the API can process.
Bulkhead limit for an API at the API level. Specifies the maximum concurrent request limit for an API, exceeding which the requests are rejected.
This number does not include the callbacks that an API receives. So, you can separately specify the maximum concurrent callbacks that an API can handle.
The 503 Service unavailable error code is sent to the client service when the requests are rejected.
You can configure the required error code and status phrase using the extended settings. You can customize the required status code and message using the extended settings pg.bulkhead.statusCode and pg.bulkhead.statusMessage respectively.
Bulkhead limit for all APIs (Global policy). Specifies the maximum concurrent request limit for all APIs.
Similar to the API level configuration, you can provide the maximum concurrent callbacks and your choice to retry the rejected requests.
When you have configured global-level bulkhead limit for APIs, and if you configure a different bulkhead limit at an API-level, then the limit configured at the global level takes precedence.
To override this, you must exclude the required APIs from the global-policy using filters. You can apply the required API filters when creating or editing the bulkhead global policy. For information about creating global policies and applying API filters
Benefits: Increases resilience and fault tolerance.
Examples: Isolating different services in a microservices architecture.
Cache-Aside #
This pattern involves explicitly loading data into a cache from the data store and writing data to the data store through the cache.
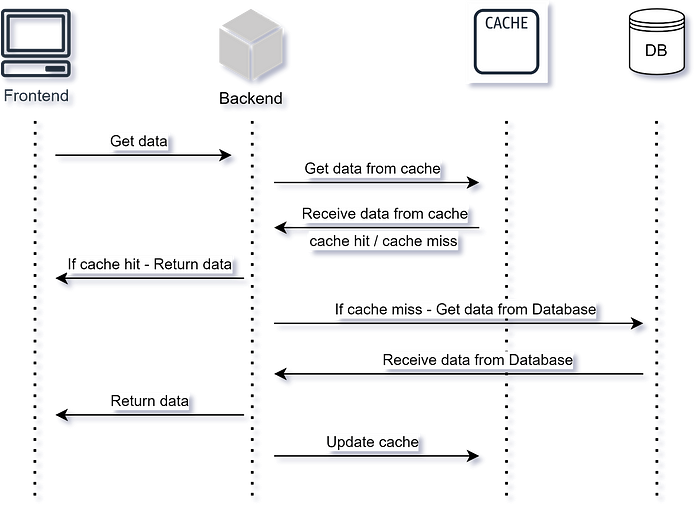
The cache-aside pattern, also known as lazy loading, involves the application code directly interacting with the cache.
When data is requested, the application first checks the cache. If the data is found, it’s returned to the user. If not, the application retrieves the data from the primary data source, stores it in the cache, and then returns it to the user.
This pattern is suitable for scenarios where the cache contains frequently accessed data, improving response times and reducing load on the primary data source.
Write-Through and Write-Behind Caching #
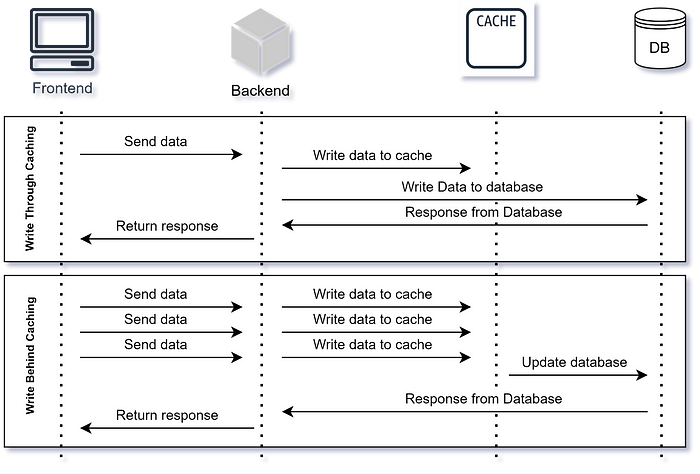
Write-through caching involves writing data to both the cache and the primary data source simultaneously.
This ensures that the cache and the primary data source remain consistent but may introduce latency due to the dual-write operation.
Write-behind caching, on the other hand, writes data to the cache first and then asynchronously updates the primary data source. While write-behind caching reduces latency, it may increase the risk of data inconsistency in case of system failures or crashes.
Read-Through and Read-Ahead Caching #
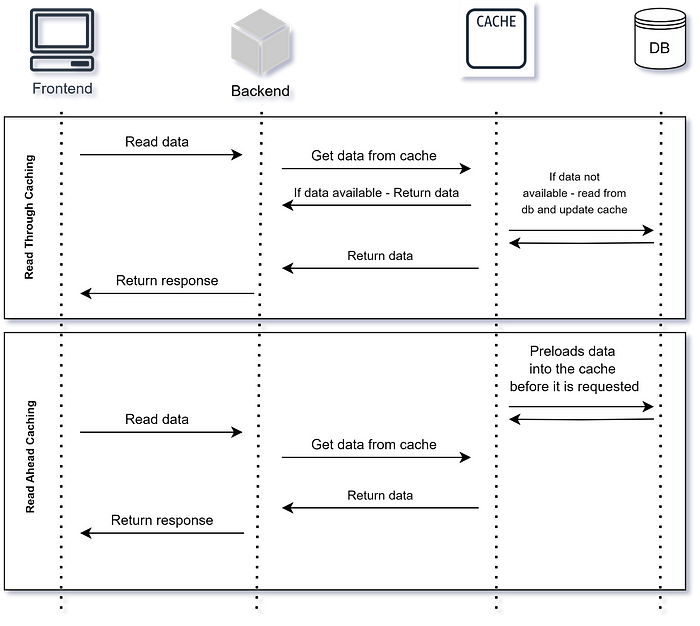
Read-through caching involves reading data from the cache. If the data is not found, it’s retrieved from the primary data source, stored in the cache, and returned to the user.
This pattern is suitable for read-heavy workloads where caching frequently accessed data can improve performance.
Read-ahead caching anticipates future data access patterns and preloads data into the cache before it’s requested. This helps reduce latency by ensuring that the required data is readily available when needed.
Benefits: Reduces load on the database, improves read performance.
Examples: Redis, Memcached.