Microservices Pattern Distributed Transactions ( Saga) by Joud W. Awad Jun, 2024 Medium
Microservices Pattern: Distributed Transactions (SAGA) | by Joud W. Awad | Jun, 2024 | Medium #
Excerpt #
Transactions are crucial in nearly all projects. In distributed systems like microservices, they present complex challenges. Our blog post simplifies this intricate topic, making it accessible and understandable.
[

]( https://medium.com/@joudwawad?source=post_page-----92b5e933cea1--------------------------------)
Introduction #
In this blog post, we delve into the intricate world of Distributed Transactions through the lens of the SAGA pattern, a pivotal strategy for managing data consistency across decentralized microservices architectures. With the shine of microservices, SAGA is almost the go-to solution when it comes to distributed transactions, Understanding how to effectively handle transactions that span multiple services becomes crucial. This discussion aims not only to clarify the fundamental principles of SAGAs but also to provide practical insights into their strategic application, ensuring robust, error-free interactions within your services.
Prerequisites #
A fundamental understanding of microservices is essential to grasp the nuances of SAGAs fully. It is recommended that readers have familiarity with the various communication mechanisms employed in microservices architectures. For those seeking to deepen their knowledge, I invite you to read my detailed blog post, “A Guide to Communication Styles in Microservices Architecture”, which offers an in-depth analysis of this subject.
From Monolithic to Microservices Architecture #
Almost every request handled by an enterprise application is executed within a database transaction. Enterprise application developers use frameworks and libraries that simplify transaction management. Some frameworks and libraries provide a programmatic API for explicitly beginning, committing, and rolling back transactions. Other frameworks, such as the Spring framework, provide a declarative mechanism.
Spring provides an @Transactional annotation that arranges for method invocations to be automatically executed within a transaction.
As a result, it’s straightforward to write transactional business logic.
Or, to be more precise, transaction management is straightforward in a monolithic application that accesses a single database. Transaction management is more challenging in a complex monolithic application that uses multiple databases and message brokers.
And in a microservice architecture, transactions span multiple services, each of which has its own database.
In this situation, the application must use a more elaborate mechanism to manage transactions. As you’ll learn in this blog post, the traditional approach of using distributed transactions isn’t a viable option for modern applications. Instead, a microservices-based application must use sagas.
The need for distributed transactions in a microservice architecture #
Imagine that you are a developer tasked with implementing a createOrder() system operation, this operation must:
- Verify that a consumer (customer) can place an order
- Verify the order details
- Authorize the consumer’s credit card
- Create an order in the database.
It’s relatively straightforward to implement this operation in a monolithic application, all the data required to validate the order is readily accessible in the monolithic. What’s more, you can use an ACID transaction to ensure data consistency.
In contrast, implementing the same operation in a microservice architecture is much more complicated.
In Microservices the needed data is scattered around multiple services, The createOrder() operation accesses data in numerous services, as shown in the following Figure

Exploring the Integration of Multiple Services in a Microservices Architecture
It reads data from Consumer Service and updates data in Order Service, Kitchen Service, and Accounting Service. Because each service has its own database, you need to use a mechanism to maintain data consistency across those databases.
The trouble with distributed transactions #
The traditional approach to maintaining data consistency across multiple services, databases, or message brokers is to use distributed transactions. The de facto standard for distributed transaction management is the X/Open Distributed Transaction Processing (DTP) Model, XA uses two-phase commit (2PC) to ensure that all participants in a transaction either commit or rollback.
An XA-compliant technology stack consists of XA-compliant databases and message brokers, database drivers, messaging APIs, and an interprocess communication mechanism that propagates the XA global transaction ID. Most SQL databases are XA compliant, as are some message brokers.
As simple as this sounds, there are a variety of problems with heterogeneous distributed transactions. One problem is that many modern technologies, including NoSQL databases such as MongoDB and Cassandra, don’t support them. Also, distributed transactions aren’t supported by modern message brokers such as RabbitMQ and Apache Kafka.
As a result if you insist on using distributed transactions, you are limited with the technologies that can support this kind of transaction.
Another problem with distributed transactions is that they are a form of synchronous IPC (Inter-process communication), which reduces availability. — In order for a distributed transaction to commit, all the participating services must be available.
the availability is the product of the availability of all of the participants in the transaction. If a distributed transaction involves two services that are 99.5% available, then the overall availability is 99%, which is significantly less. Each additional service involved in a distributed transaction further reduces availability.
On the surface, distributed transactions are appealing. From a developer’s perspective, they have the same programming model as local transactions. But because of the problems mentioned so far, distributed transactions aren’t a viable technology for modern applications.
Using the SAGA pattern to maintain data consistency #
SAGAs are mechanisms to maintain data consistency in a microservice architecture without having to use distributed transactions. You define a SAGA for each system command that needs to update data in multiple services. A SAGA is a sequence of local transactions. Each local transaction updates data within a single service using the familiar ACID transaction frameworks and libraries.
The system operation initiates the first step of the SAGA. The completion of a local transaction triggers the execution of the next local transaction.
Later you’ll see how coordination of the steps is implemented using asynchronous messaging. An important benefit of asynchronous messaging is that it ensures that all the steps of a SAGA are executed, even if one or more of the saga’s participants are temporarily unavailable.
SAGAs differ from ACID transactions in a couple of important ways. They lack the isolation property of ACID transactions.
AN EXAMPLE SAGA: The `createOrder` SAGA #
The example saga used throughout this blog post is the Create Order SAGA, which is shown in the following figure. The Order Service implements the createOrder() operation using this SAGA. The SAGA’s first local transaction is initiated by the external request to create an order. The other five local transactions are each triggered by the completion of the previous one.
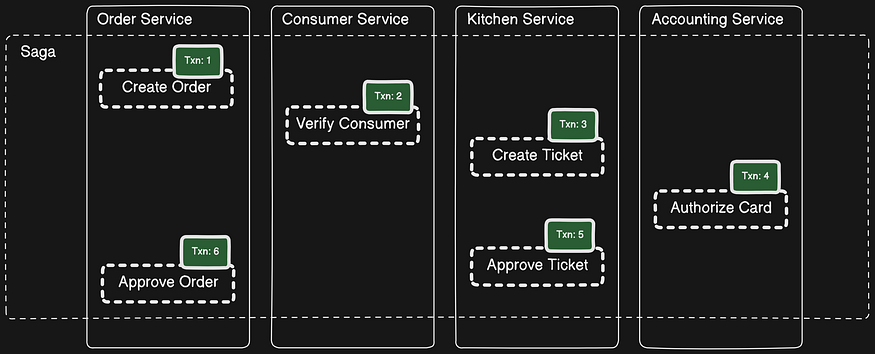
This saga consists of the following local transactions:
- Order Service — Create an Order in an
APPROVAL_PENDINGstate. - Consumer Service — Verify that the consumer can place an order.
- Kitchen Service — Validate order details and create a Ticket in the
CREATE_PENDING. - Accounting Service — Authorize consumer’s credit card.
- Kitchen Service — Change the state of the Ticket to
AWAITING_ACCEPTANCE. - Order Service — Change the state of the Order to
APPROVED.
A service publishes a message when a local transaction is completed.
This message then triggers the next step in the SAGA, not only does using messaging ensure the SAGA participants are loosely coupled, it also guarantees that a SAGA completes. That’s because if the recipient of a message is temporarily unavailable, the message broker buffers the message until it can be delivered.
SAGAs use compensating transactions to roll back changes #
A great feature of traditional ACID transactions is that the business logic can easily roll back a transaction if it detects a violation of a business rule. It executes a ROLL-BACK statement, and the database undoes all the changes made so far. Unfortunately, SAGAs can’t be automatically rolled back, because each step commits its changes to the local database.
This means, for example, that if the authorization of the credit card fails in the fourth step of the Create Order SAGA, the application must explicitly undo the changes made by the first three steps. You must write what are known as compensating transactions.
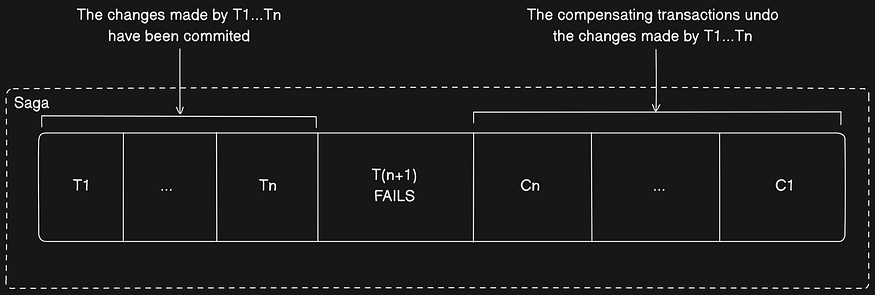
The SAGA executes the compensation transactions in reverse order of the forward transactions:
Cn … C1. The mechanics of sequencing the C(i)saren’t any different than sequencing the T(i)s.
The completion of C(i) must trigger the execution of C(i-1).
Consider, for example, the Create Order SAGA. This SAGA can fail for a variety of reasons:
- The consumer information is invalid or the consumer isn’t allowed to create orders.
- The restaurant information is invalid or the restaurant is unable to accept orders.
- The authorization of the consumer’s credit card fails.
If a local transaction fails, the saga’s coordination mechanism must execute compensating transactions that reject the Order and possibly the Ticket.
The following table shows the compensating transactions for each step of the Create Order SAGA. It’s important to note that not all steps need compensating transactions.
Read-only steps, such as verifyConsumerDetails(), don’t need compensating transactions. Nor do steps such as authorizeCreditCard()that are followed by steps that always succeed.
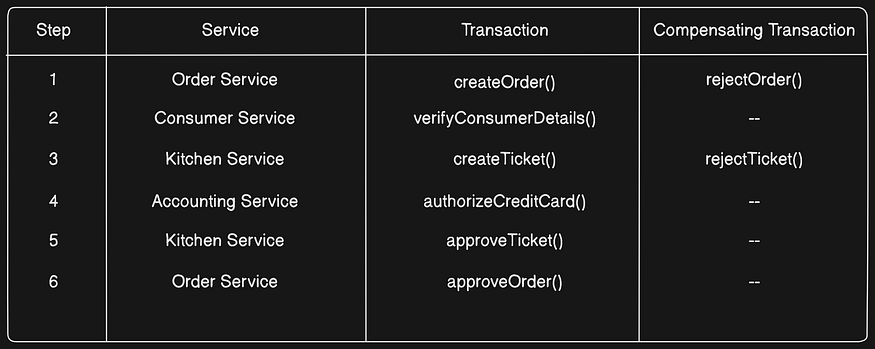
To see how compensating transactions are used, imagine a scenario where the authorization of the consumer’s credit card fails. In this scenario, the SAGA executes the following local transactions:
- Order Service — Create an Order in an
APPROVAL_PENDINGstate. - Consumer Service — Verify that the consumer can place an order.
- Kitchen Service — Validate order details and create a Ticket in the
CREATE_PENDINGstate. - Accounting Service — Authorize consumer’s credit card, which fails.
- Kitchen Service — Change the state of the Ticket to
CREATE_REJECTED. - Order Service — Change the state of the Order to
REJECTED.
The fifth and sixth steps are compensating transactions that undo the updates made by Kitchen Service and Order Service, respectively.
A SAGA’s coordination logic is responsible for sequencing the execution of forward and compensating transactions. Let’s look at how that works.
Coordinating SAGAs #
A SAGA’s implementation consists of logic that coordinates the steps of the saga.
When a SAGA is initiated by a system command, the coordination logic must select and tell the first SAGA participant to execute a local transaction. Once that transaction is completed, the SAGA’s sequencing coordination selects and invokes the next saga participant.
This process continues until the SAGA has executed all the steps.
If any local transaction fails, the SAGA must execute the compensating transactions in reverse order. There are a couple of different ways to structure a saga’s coordination logic:
- Choreography — Distribute the decision-making and sequencing among the saga participants. They primarily communicate by exchanging events.
- Orchestration — Centralize a SAGA’s coordination logic in a SAGA orchestrator class. A SAGA orchestrator sends command messages to SAGA participants telling them which operations to perform.
Let’s look at each option.
Choreography-based SAGAs #
One way you can implement a SAGA is by using choreography. When using choreography, there’s no central coordinator telling the SAGA participants what to do. Instead, the SAGA participants subscribe to each other’s events and respond accordingly.
Let us implement the createOrder SAGA using CHOREOGRAPHY
The following figure shows the design of the choreography-based version of the Create Order SAGA. The participants communicate by exchanging events. Each participant, starting with the Order Service, updates its database and publishes an event that triggers the next participant.
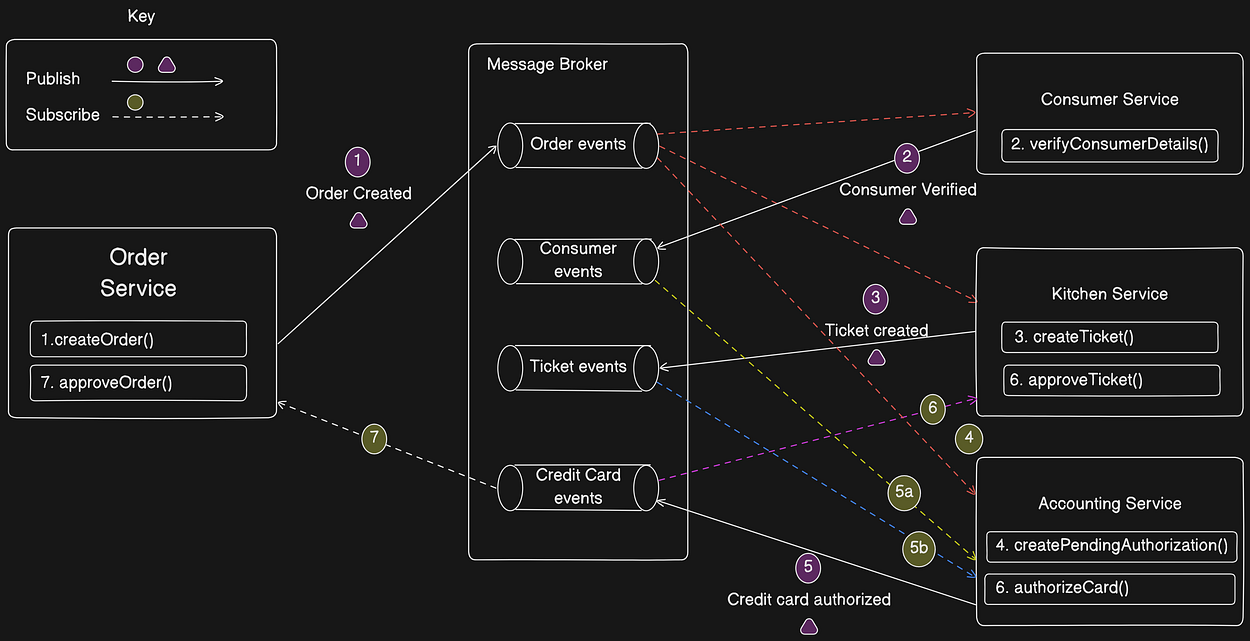
CHOREOGRAPHY SAGA Flow
The HAPPY path through this SAGA is as follows:
- Order Service creates an Order in the
APPROVAL_PENDINGstate and publishes anOrderCreatedevent. - Consumer Service consumes the
OrderCreatedevent, verifies that the consumer can place the order, and publishes aConsumerVerifiedevent. - Kitchen Service consumes the
OrderCreatedevent, validates the Order, creates a Ticket in aCREATE_PENDINGstate, and publishes theTicketCreatedevent. - Accounting Service consumes the
OrderCreateevent and creates aCreditCardAuthorizationin aPENDINGstate. - Accounting Service consumes the
TicketCreatedandConsumerVerifiedevents, charge the consumer’s credit card, and publish theCreditCardAuthorizedevent. - Kitchen Service consumes the CreditCardAuthorized event and changes the state of the Ticket to
AWAITING_ACCEPTANCE. - Order Service receives the
CreditCardAuthorizedevents, changes the state of the Order toAPPROVED, and publishes anOrderApprovedevent.
The Create Order SAGA must also handle the scenario where a SAGA participant rejects the Order and publishes some kind of failure event.
For example, the authorization of the consumer’s credit card might fail. The SAGA must execute the compensating transactions to undo what’s already been done.
The following figure shows the flow of events when the AccountingService can’t authorize the consumer’s credit card.
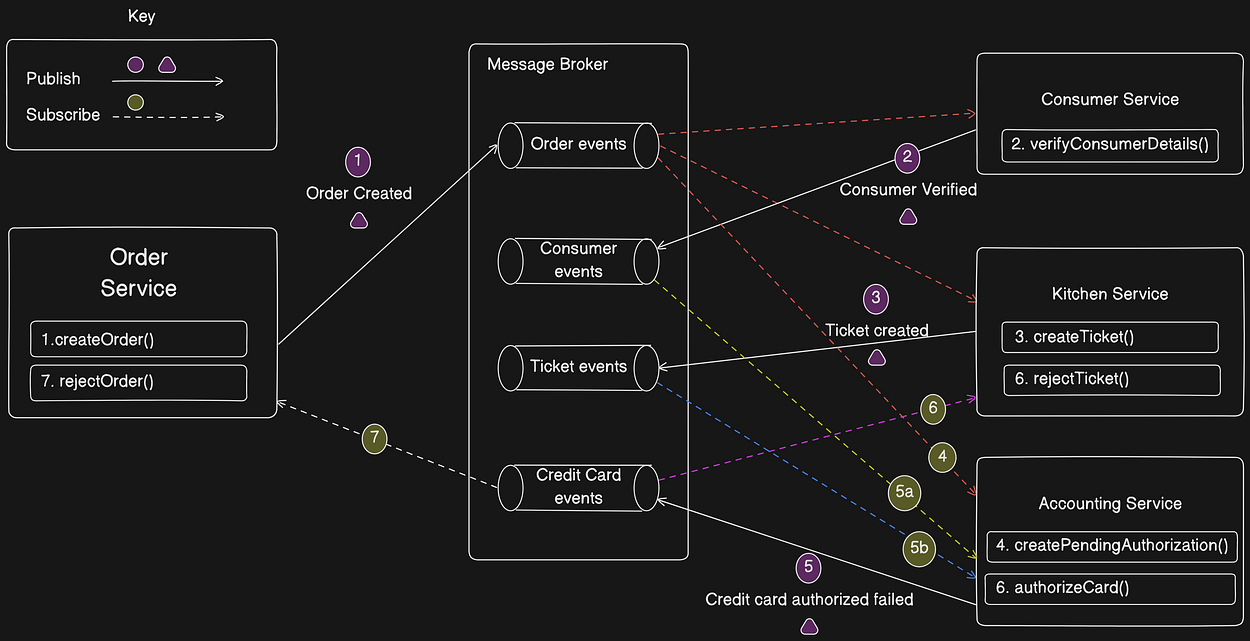
The sequence of events is as follows:
- Order Service creates an Order in the
APPROVAL_PENDINGstate and publishes anOrderCreatedevent. - Consumer Service consumes the
OrderCreatedevent, verifies that the consumer can place the order, and publishes aConsumerVerifiedevent. - Kitchen Service consumes the
OrderCreatedevent, validates the Order, creates a Ticket in aCREATE_PENDINGstate, and publishes theTicketCreatedevent. - Accounting Service consumes the
OrderCreatedevent and creates aCreditCardAuthorizationin aPENDINGstate. - Accounting Service consumes the
TicketCreatedandConsumerVerifiedevents, charge the consumer’s credit card, and publish aCreditCardAuthorizationFailedevent. - Kitchen Service consumes the
CreditCardAuthorizationFailedevent and changes the state of the Ticket toREJECTED. - Order Service consumes the
CreditCardAuthorizationFailedevent and changes the state of the Order toREJECTED.
As you can see, the participants of choreography-based SAGAs interact using publish/subscribe. Let’s take a closer look at some issues you’ll need to consider when implementing publish/subscribe-based communication for your SAGAs.
Reliable Event-Based communication #
There are a couple of interservice communication-related issues that you must consider when implementing choreography-based SAGAs:
- The first issue is ensuring that a SAGA participant updates its database and publishes an event as part of a database transaction. Each step of a choreography-based SAGA updates the database and publishes an event. For example, in the Create Order SAGA, Kitchen Service receives a Consumer Verified event, creates a Ticket, and publishes a Ticket Created event.
It’s essential that the database update and the publishing of the event happen atomically. Consequently, to communicate reliably, the SAGA participants must use transactional messaging - The second issue you need to consider is ensuring that a saga participant must be able to map each event that it receives to its own data. For example, when Order Service receives a
CreditCardAuthorizedevent, it must be able to look up the corresponding Order. The solution is for a SAGA participant to publish events containing a*correlationId*, which is data that enables other participants to perform the mapping. For example, the participants of the Create Order Saga can use the orderId as a correlation Id that’s passed from one participant to the next. Accounting Service publishes aCreditCardAuthorizedevent containing the orderId from theTicketCreatedevent.
Benefits and Drawbacks of Choreography-Based SAGAs #
Choreography-based SAGAs have several benefits:
- Simplicity — Services publish events when they create, update, or delete business objects.
- Loose coupling — The participants subscribe to events and don’t have direct knowledge of each other.
And there are some drawbacks:
- More difficult to understand — Unlike with orchestration, there isn’t a single place in the code that defines the SAGA. Instead, choreography distributes the implementation of the SAGA among the services. Consequently, it’s sometimes difficult for a developer to understand how a given SAGA works.
- Cyclic dependencies between the services — The SAGA participants subscribe to each other’s events, which often creates cyclic dependencies. For example, if you carefully examine the previous diagrams, you’ll see that there are cyclic dependencies, such as
Order Service → Accounting Service → Order Service. Although this isn’t necessarily a problem, cyclic dependencies are considered a design smell. - Risk of tight coupling — Each SAGA participant needs to subscribe to all events that affect them. For example, the Accounting Service must subscribe to all events that cause the consumer’s credit card to be charged or refunded. As a result, there’s a risk that it would need to be updated in lockstep with the order lifecycle implemented by Order Service.
Orchestration-based sagas #
Orchestration is another way to implement SAGAs. When using orchestration, you define an orchestrator class whose sole responsibility is to tell the SAGA participants what to do. The SAGA orchestrator communicates with the participants using command/async reply-style interaction.
To execute a SAGA step, it sends a command message to a participant telling it what operation to perform. After the SAGA participant has performed the operation, it sends a reply message to the orchestrator. The orchestrator then processes the message and determines which SAGA step to perform next.
Let us implement the createOrder SAGA using ORCHESTRATION
The following figure shows the design of the orchestration-based version of the Create Order SAGA. The SAGA is orchestrated by the CreateOrderSaga class, which invokes the SAGA participants using asynchronous request/response.
This class keeps track of the process and sends command messages to SAGA participants, such as Kitchen Service and Consumer Service.
The CreateOrderSaga class reads reply messages from its reply channel and then determines the next step, if any, in the saga.
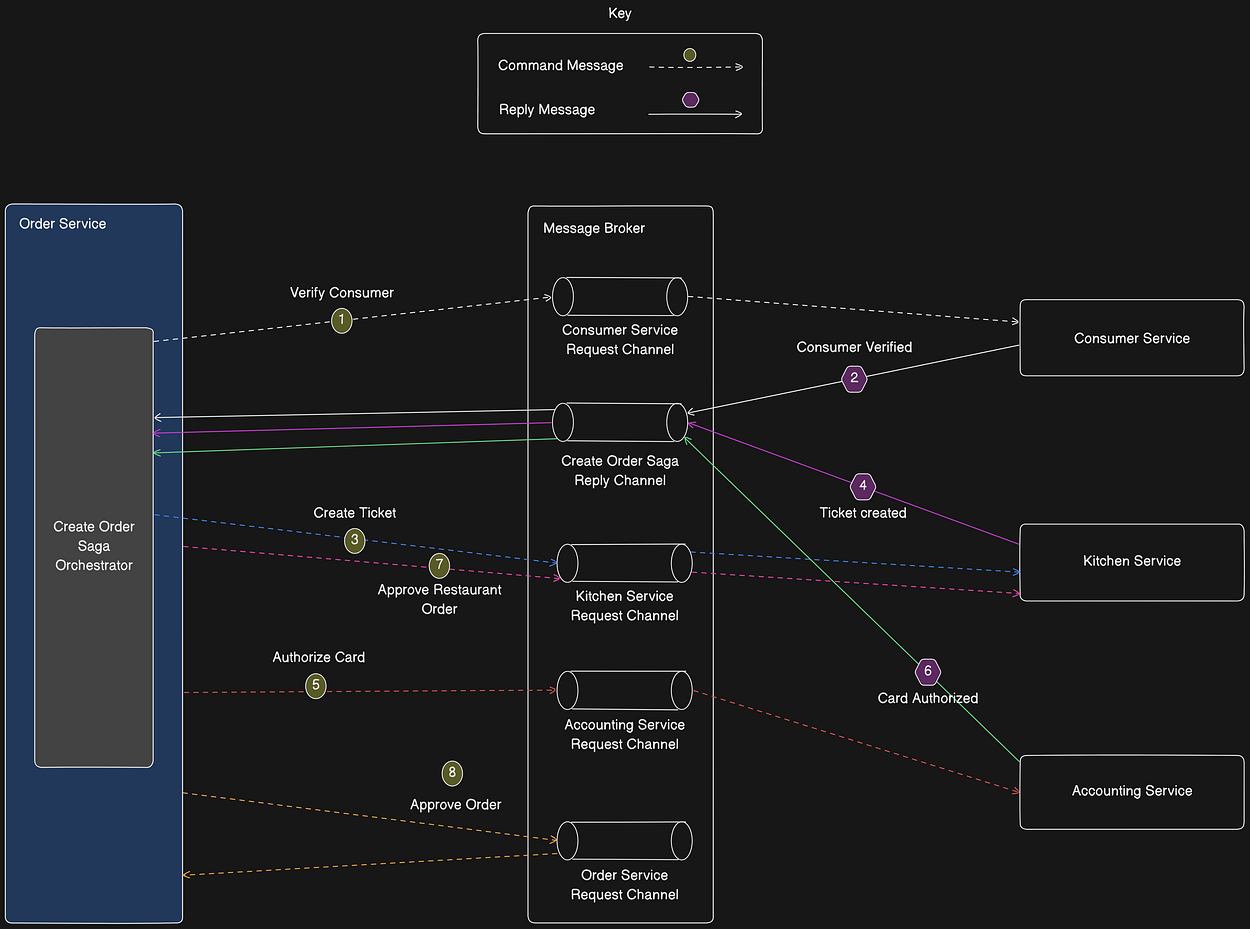
ORCHESTRATION SAGA Flow
Order Service first creates an Order and a Create Order SAGA orchestrator After that, the flow for the happy path is as follows:
- The SAGA orchestrator sends a
Verify Consumercommand to Consumer Service. - Consumer Service replies with a
Consumer Verifiedmessage. - The SAGA orchestrator sends a
Create Ticketcommand to Kitchen Service. - Kitchen Service replies with a
Ticket Createdmessage. - The SAGA orchestrator sends an
Authorize Cardmessage to Accounting Service. - Accounting Service replies with a
Card Authorizedmessage. - The SAGA orchestrator sends an
Approve Ticketcommand to Kitchen Service. - The saga orchestrator sends an
Approve Ordercommand to Order Service.
Note that in the final step, the SAGA orchestrator sends a command message to Order Service, even though it’s a component of Order Service. In principle, the Create Order Saga could approve the Order by updating it directly. But in order to be consistent, the SAGA treats Order Service as just another participant.
I understand that SAGAs can be complex, but for practical applications, this example reflects a typical workflow. I aim to provide a realistic scenario in this blog post to enhance understanding of real-world implementations.
SAGA Orchestration & Transactional Messaging #
Each step of an orchestration-based SAGA consists of a service updating a database and publishing a message. For example, Order Service persists an Order and a Create Order Saga orchestrator and sends a message to the first SAGA participant.
A SAGA participant, such as Kitchen Service, handles a command message by updating its database and sending a reply message. Order Service processes the participant’s reply message by updating the state of the SAGA orchestrator and sending a command message to the next saga participant.
a service must use transactional messaging in order to atomically update the database and publish messages.
Benefits and Drawbacks of Orchestration-Based SAGAs #
Orchestration-based SAGAs have several benefits:
- Simpler dependencies — One benefit of orchestration is that it doesn’t introduce cyclic dependencies. The SAGA orchestrator invokes the SAGA participants, but the participants don’t invoke the orchestrator. As a result, the orchestrator depends on the participants but not vice versa, and so there are no cyclic dependencies.
- Loss coupling — Each service implements an API that is invoked by the orchestrator, so it does not need to know about the events published by the SAGA participants.
- Improves separation of concerns and simplifies the business logic — The SAGA coordination logic is localized in the SAGA orchestrator. The domain objects are simpler and have no knowledge of the SAGAs that they participate in. For example, when using orchestration, the Order class has no knowledge of any of the SAGAs, so it has a simpler state machine model. During the execution of the Create Order SAGA, it transitions directly from the
APPROVAL_PENDINGstate to theAPPROVEDstate. The Order class doesn’t have any intermediate states corresponding to the steps of the SAGA. As a result, the business is much simpler.
Orchestration also has a drawback: the risk of centralizing too much business logic in the orchestrator. This results in a design where the smart orchestrator tells the dumb services what operations to do. Fortunately, you can avoid this problem by designing orchestrators that are solely responsible for sequencing and don’t contain any other business logic.
Handling the lack of isolation #
The I in ACID stands for isolation. The isolation property of ACID transactions ensures that the outcome of executing multiple transactions concurrently is the same as if they were executed in some serial order.
The database provides the illusion that each ACID transaction has exclusive access to the data. Isolation makes it a lot easier to write business logic that executes concurrently.
The challenge with using SAGAs is that they lack the isolation property of ACID transactions. That’s because the updates made by each of a SAGA’s local transactions are immediately visible to other SAGAs once that transaction commits.
This behavior can cause two problems:
- First, other SAGAs can change the data accessed by the SAGA while it’s executing.
- The other SAGAs can read its data before the SAGA has completed its updates, and consequently can be exposed to inconsistent data.
You can, in fact, consider a SAGA to be ACD:
- Atomicity — The SAGA implementation ensures that all transactions are executed or all changes are undone.
- Consistency — Referential integrity within a service is handled by local databases. Referential integrity across services is handled by the services.
- Durability — Handled by local databases.
This lack of isolation potentially causes what the database literature calls anomalies.
An anomaly is when a transaction reads or writes data in a way that it wouldn’t if transactions were executed one at a time.
When an anomaly occurs, the outcome of executing SAGAs concurrently is different than if they were executed serially.
Next, we discuss a set of SAGA design strategies that deal with the lack of isolation, these strategies are known as countermeasures Some countermeasures implement isolation at the application level. Other countermeasures reduce the business risk of the lack of isolation.
By using countermeasures, you can write SAGA-based business logic that works correctly.
Overview of anomalies #
The lack of isolation can cause the following three anomalies:
- Lost updates — One SAGA overwrites without reading changes made by another saga.
- Dirty reads — A transaction or a SAGA reads the updates made by a saga that has not yet completed those updates.
- Fuzzy/nonrepeatable reads — Two different steps of a SAGA read the same data and get different results because another SAGA has made updates.
All three anomalies can occur, but the first two are the most common and the most challenging. Let’s take a look at those two types of anomaly, starting with lost updates.
LOST UPDATES #
A lost update anomaly occurs when one SAGA overwrites an update made by another SAGA.
Consider, for example, the following scenario:
- The first step of the Create Order SAGA creates an Order.
- While that SAGA is executing, the Cancel Order SAGA cancels the Order.
- The final step of the Create Order SAGA approves the Order.
In this scenario, the Create Order SAGA ignores the update made by the Cancel Order Saga and overwrites it. As a result, the application will ship an order that the customer had canceled.
DIRTY READS #
A dirty read occurs when one SAGA reads data that’s in the middle of being updated by another SAGA.
Consider, for example, a version of the application where consumers have a credit limit. In this application, a SAGA that cancels an order consists of the following transactions:
- Consumer Service — Increase the available credit.
- Order Service — Change the state of the Order to cancel.
- Delivery Service — Cancel the delivery.
Let’s imagine a scenario that interleaves the execution of the Cancel Order and Create Order SAGAs, and the Cancel Order SAGA is rolled back because it’s too late to cancel the delivery.
It’s possible that the sequence of transactions that invoke the Consumer Service is as follows:
- Cancel Order SAGA — Increase the available credit.
- Create Order SAGA — Reduce the available credit.
- Cancel Order SAGA — A compensating transaction that reduces the available credit.
In this scenario, the Create Order SAGA does a dirty read of the available credit that enables the consumer to place an order that exceeds their credit limit. It’s likely that this is an unacceptable risk to the business.
Let’s look at how to prevent this and other kinds of anomalies from impacting an application.
Countermeasures for handling the lack of isolation #
The SAGA transaction model is ACD, and its lack of isolation can result in anomalies that cause applications to misbehave. It’s the responsibility of the developer to write SAGAs in a way that either prevents the anomalies or minimizes their impact on the business. This may sound like a daunting task, but you’ve already seen an example of a strategy that prevents anomalies. An Order’s use of *_PENDING states, such as APPROVAL_PENDING, is an example of one such strategy.
SAGAs that update Orders, such as the Create Order SAGA, begin by setting the state of an Order to *_PENDING. The *_PENDING state tells other transactions that the Order is being updated by a SAGA and to act accordingly.
An Order’s use of *_PENDING states is an example of what the 1998 paper “Semantic ACID properties in multidatabases using remote procedure calls and update propagations” by Lars Frank and Torben U. Zahle calls a semantic lock countermeasure.
The paper describes how to deal with the lack of transaction isolation in multi-database architectures that don’t use distributed transactions. Many of its ideas are useful when designing SAGAs.
It describes a set of countermeasures for handling anomalies caused by lack of isolation that either prevent one or more anomalies or minimize their impact on the business.
The countermeasures described by this paper are as follows:
- Semantic lock — An application-level lock.
- Commutative updates — Design update operations to be executable in any order.
- Pessimistic view — Reorder the steps of a saga to minimize business risk.
- Reread value — Prevent dirty writes by rereading data to verify that it’s unchanged before overwriting it.
- Version file — Record the updates to a record so that they can be reordered.
- By value — Use each request’s business risk to dynamically select the concurrency mechanism.
The structure of a SAGA #
The countermeasures paper mentioned in the last section defines a useful model for the structure of a SAGA. In this model, shown in the figure below, a SAGA consists of three types of transactions:
- Compensatable transactions — Transactions that can potentially be rolled back using a compensating transaction.
- Pivot transaction — The go/no-go point in a saga. If the pivot transaction commits, the saga will run until completion. A pivot transaction can be a transaction that’s neither compensatable nor retriable. Alternatively, it can be the last compensatable transaction or the first retriable transaction.
- Retriable transactions — Transactions that follow the pivot transaction and are guaranteed to succeed.
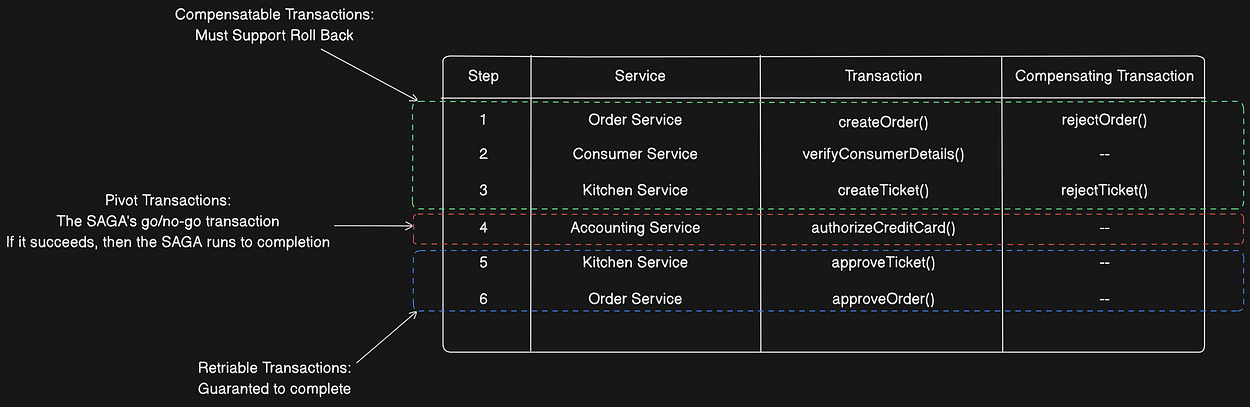
SAGA Structure
in the create order SAGA:
- The
createOrder(), verifyConsumerDetails(), and createTicket()steps are compensatable transactions. - The
createOrder() and createTicket()transactions have compensating transactions that undo their updates. - The
verifyConsumerDetails()transaction is read-only, so doesn’t need a compensating transaction. - The
authorizeCreditCard()transaction is this SAGA’s pivot transaction. If the consumer’s credit card can be authorized, this SAGA is guaranteed to complete. - The
approveTicket()andapproveOrder()steps are retriable transactions that follow the pivot transaction.
The distinction between compensatable transactions and retriable transactions is especially important.
As you’ll see, each type of transaction plays a different role in the countermeasures.
Let’s now look at each countermeasure, starting with the semantic lock countermeasure.
COUNTERMEASURE: SEMANTIC LOCK #
Adds a lock to the row we are creating or updating so it can be locked from other consumers.
When using the semantic lock countermeasure, a SAGA’s compensatable transaction sets a flag in any record that it creates or updates.
The flag indicates that the record isn’t committed and could potentially change.
The flag can either be a lock that prevents other transactions from accessing the record or a warning that indicates that other transactions should treat that record with suspicion.
It’s cleared by either a retriable transaction — SAGA is completing successfully — or by a compensating transaction: the saga is rolling back.
The Order.state field is a great example of a semantic lock. The *_PENDING states, such as APPROVAL_PENDING and REVISION_PENDING, implement a semantic lock. They tell other SAGAs that access an Order that a SAGA is in the process of updating the Order.
For instance, the first step of the Create Order SAGA, which is a compensatable transaction, creates an Order in an APPROVAL_PENDING state. The final step of the Create Order SAGA, which is a retriable transaction, changes the field to APPROVED. A compensating transaction changes the field to REJECTED.
Managing the lock is only half the problem. You also need to decide on a case-by-case basis how a SAGA should deal with a record that has been locked. Consider, for example, the cancelOrder() system command. A client might invoke this operation to cancel an Order that’s in the APPROVAL_PENDING state.
There are a few different ways to handle this scenario.
- One option is for the
cancelOrder()system command to fail and tell the client to try again later. The main benefit of this approach is that it’s simple to implement. The drawback, however, is that it makes the client more complex because it has to implement retry logic. - Another option is for
cancelOrder()to block until the lock is released.
COUNTERMEASURE: COMMUTATIVE UPDATES #
Design the SAGA so it can be executed in any order ~ an example would be an increase and decrease of an account blanace.
One straightforward countermeasure is to design the update operations to be commutative. Operations are commutative if they can be executed in any order.
An Account’s debit() and credit() operations are commutative (if you ignore overdraft checks). This countermeasure is useful because it eliminates lost updates.
Consider, for example, a scenario where a SAGA needs to be rolled back after a compensatable transaction has debited (or credited) an account. The compensating transaction can simply credit (or debit) the account to undo the update. There’s no possibility of overwriting updates made by other SAGAs.
COUNTERMEASURE: PESSIMISTIC VIEW #
It reorders the steps of a SAGA to minimize business risk due to a dirty read.
Consider, for example, the scenario earlier used to describe the dirty read anomaly. In that scenario, the Create Order SAGA performed a dirty read of the available credit and created an order that exceeded the consumer credit limit. To reduce the risk of that happening, this countermeasure would reorder the Cancel Order SAGA:
- Order Service — Change the state of the Order to cancelled.
- Delivery Service — Cancel the delivery.
- Customer Service — Increase the available credit.
In this reordered version of the SAGA, the available credit is increased in a retriable transaction, which eliminates the possibility of a dirty read.
COUNTERMEASURE: REREAD VALUE #
A SAGA that uses this countermeasure re-reads a record before updating it, verifies that it’s unchanged, and then updates the record. If the record has changed, the saga aborts and possibly restarts.
The reread value countermeasure prevents lost updates.
A SAGA that uses this countermeasure rereads a record before updating it, verifies that it’s unchanged, and then updates the record. If the record has changed, the SAGA aborts and possibly restarts. This countermeasure is a form of the Optimistic Offline Lock pattern.
The Create Order SAGA could use this countermeasure to handle the scenario where the Order is canceled while it’s in the process of being approved.
The transaction that approves the Order verifies that the Order is unchanged since it was created earlier in the SAGA. If it’s unchanged, the transaction approves the Order. But if the Order has been cancelled, the transaction aborts the SAGA, which causes its compensating transactions to be executed.
COUNTERMEASURE: VERSION FILE #
it records the operations that are performed on a record so that it can execute them in an order.
The version file countermeasure is so named because it records the operations that are performed on a record so that it can reorder them. It’s a way to turn noncommutative operations into commutative operations.
To see how this countermeasure works, consider a scenario where the Create Order SAGA executes concurrently with a Cancel Order SAGA. Unless the sagas use the semantic lock countermeasure, it’s possible that the Cancel Order SAGA cancels the authorization of the consumer’s credit card before the Create Order Saga authorizes the card.
One way for the Accounting Service to handle these out-of-order requests is for it to record the operations as they arrive and then execute them in the correct order. In this scenario, it would first record the Cancel Authorization request. Then, when the Accounting Service receives the subsequent Authorize Card request, it would notice that it had already received the Cancel Authorization request and skip authorizing the credit card.
COUNTERMEASURE: BY VALUE #
It’s a strategy for selecting concurrency mechanisms based on business risk. uses the properties of each request to decide between using sagas and distributed transactions
The final countermeasure is the by value countermeasure. It’s a strategy for selecting concurrency mechanisms based on business risk. An application that uses this countermeasure uses the properties of each request to decide between using SAGAs and distributed transactions.
It executes low-risk requests using SAGAs, perhaps applying the countermeasures described in the preceding section. But it executes high-risk requests involving, for example, large amounts of money, using distributed transactions.
This strategy enables an application to dynamically make trade-offs about business risk, availability, and scalability.
It’s likely that you’ll need to use one or more of these countermeasures when implementing SAGAs in your application.
Conclusion #
Distributed transactions, particularly SAGAs, are complex subjects. In this blog post, we have endeavored to provide a comprehensive overview of SAGAs, explaining their mechanisms, applications, and how to navigate their limitations effectively. I hope you have found this discussion informative. Should you have any questions or wish to further the conversation, please feel free to leave your comments.
References #
- Microservices Patterns — Chris Richardson
- Building Microservices: Designing Fine-Grained Systems 2nd Edition — Sam Newman