How an Empty S3 Bucket Can Make Your Aws Bill Explode by Maciej Pocwierz Apr, 2024 Medium
How an empty S3 bucket can make your AWS bill explode | by Maciej Pocwierz | Apr, 2024 | Medium #
Excerpt #
Imagine you create an empty, private AWS S3 bucket in a region of your preference. What will your AWS bill be the next morning?
Imagine you create an empty, private AWS S3 bucket in a region of your preference. What will your AWS bill be the next morning?
A few weeks ago, I began working on the PoC of a document indexing system for my client. I created a single S3 bucket in the eu-west-1 region and uploaded some files there for testing. Two days later, I checked my AWS billing page, primarily to make sure that what I was doing was well within the free-tier limits. Apparently, it wasn’t. My bill was over $1,300, with the billing console showing nearly 100,000,000 S3 PUT requests executed within just one day!
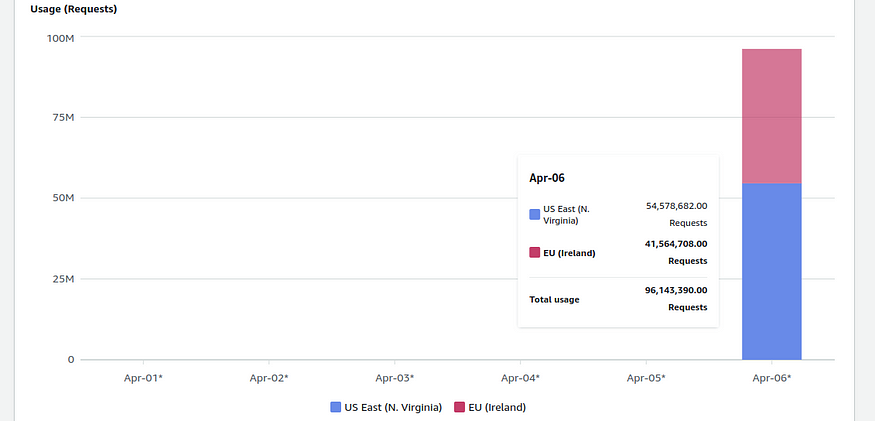
My billed S3 usage per day, per region
Where were these requests coming from? #
By default, AWS doesn’t log requests executed against your S3 buckets. However, such logs can be enabled using AWS CloudTrail or S3 Server Access Logging. After enabling CloudTrail logs, I immediately observed thousands of write requests originating from multiple accounts or entirely outside of AWS.
But why would some third parties bombard my S3 bucket with unauthorised requests? #
Was it some kind of DDoS-like attack against my account? Against AWS? As it turns out, one of the popular open-source tools had a default configuration to store their backups in S3. And, as a placeholder for a bucket name, they used… the same name that I used for my bucket. This meant that every deployment of this tool with default configuration values attempted to store its backups in my S3 bucket!
Note: I can’t disclose the name of the tool I’m referring to, as that would put the impacted companies at risk of data leak (as explained further).
So, a horde of misconfigured systems is attempting to store their data in my private S3 bucket. But why should I be the one paying for this mistake? Here’s why:
S3 charges you for unauthorized incoming requests #
This was confirmed in my exchange with AWS support. As they wrote:
Yes, S3 charges for unauthorized requests (4xx) as well[1]. That’s expected behavior.
So, if I were to open my terminal now and type:
<span id="8e15" data-selectable-paragraph="">aws s3 <span>cp</span> ./file.txt s3://your-bucket-name/random_key</span>
I would receive an AccessDenied error, but you would be the one to pay for that request. And I don’t even need an AWS account to do so.
Another question was bugging me: why was over half of my bill coming from the us-east-1 region? I didn’t have a single bucket there! The answer to that is that the S3 requests without a specified region default to us-east-1 and are redirected as needed. And the bucket’s owner pays extra for that redirected request.
The security aspect #
We now understand why my S3 bucket was bombarded with millions of requests and why I ended up with a huge S3 bill. At that point, I had one more idea I wanted to explore. If all those misconfigured systems were attempting to back up their data into my S3 bucket, why not just let them do so? I opened my bucket for public writes and collected over 10GB of data within less than 30 seconds. Of course, I can’t disclose whose data it was. But it left me amazed at how an innocent configuration oversight could lead to a dangerous data leak!
What did I learn from all this? #
Lesson 1: Anyone who knows the name of any of your S3 buckets can ramp up your AWS bill as they like. #
Other than deleting the bucket, there’s nothing you can do to prevent it. You can’t protect your bucket with services like CloudFront or WAF when it’s being accessed directly through the S3 API. Standard S3 PUT requests are priced at just $0.005 per 1,000 requests, but a single machine can easily execute thousands of such requests per second.
Lesson 2: Adding a random suffix to your bucket names can enhance security. #
This practice reduces vulnerability to misconfigured systems or intentional attacks. At least avoid using short and common names for your S3 buckets.
Lesson 3: When executing a lot of requests to S3, make sure to explicitly specify the AWS region. #
This way you will avoid additional costs of S3 API redirects.
Aftermath: #
- I reported my findings to the maintainers of the vulnerable open-source tool. They quickly fixed the default configuration, although they can’t fix the existing deployments.
- I notified the AWS security team. I suggested that they restrict the unfortunate S3 bucket name to protect their customers from unexpected charges, and to protect the impacted companies from data leaks. But they were unwilling to address misconfigurations of third-party products.
- I reported the issue to two companies whose data I found in my bucket. They did not respond to my emails, possibly considering them as spam.
- AWS was kind enough to cancel my S3 bill. However, they emphasized that this was done as an exception.
Thank you for taking the time to read my post. I hope it will help you steer clear of unexpected AWS charges!