The Design Patterns for Distributed Systems Handbook – Key Concepts Every Developer Should Know
The Design Patterns for Distributed Systems Handbook – Key Concepts Every Developer Should Know #
Excerpt #
When I first started my career as a backend engineer, I always worked with monolithic systems.
The work was good but I always had this thought in the back of my mind:
“Man, I want to work on big systems such as ones for Google, Netflix, etc…” I was 19 and a junior developer, so cut me some slack here.
I didn’t even know the term distributed systems until one of my colleagues started talking about it.
Then I researched it – I researched a lot. It seemed very complicated, and I felt very

When I first started my career as a backend engineer, I always worked with monolithic systems.
The work was good but I always had this thought in the back of my mind:
“Man, I want to work on big systems such as ones for Google, Netflix, etc…”
I was 19 and a junior developer, so cut me some slack here.
I didn’t even know the term distributed systems until one of my colleagues started talking about it.
Then I researched it – I researched a lot. It seemed very complicated, and I felt very stupid.
But I was excited.
I studied this concept of distributed systems for a while, but didn’t fully understand it until I saw it all in action a few years later.
Now that I have some experience, I would like to share with you what I know about distributed systems.
Prerequisite Knowledge #
The topics I’ll be discussing here may be a bit advanced for beginner programmers. To help you be prepared, here’s what I assume you know:
- Mid Level Programming (any language will work)
- Basic Computer Networking (TCP/IP, network protocols, and so on)
- Basic Data Structures and Algorithms (Big O notation, search, sort, and so on)
- Databases (Relational, NoSQL, and so on)
If that sounds like a lot, don’t feel discouraged.
Here are some resources that can help you brush up on some of these more specific topics:
- Learn how computer networks work in this free course
- Learn about data structures and algorithms in this free course
- Learn about relational databases here, and about NoSQL databases here.
Here’s What We’ll Cover: #
- What are Distributed Systems?
- Common Challenges in Distributed Systems
- Command and Query Responsibility Segregation (CQRS) Pattern
- Two-Phase Commit (2PC) Pattern
- Saga Pattern
- Replicated Load-Balanced Services (RLBS) Pattern
- Sharded Services Pattern
- Sidecar Pattern
- Write-Ahead Log Technique
- Split-Brain Pattern
- Hinted Handoff Pattern
- Read Repair Pattern
- Service Registry Pattern
- Circuit Breaker Pattern
- Leader Election Pattern
- Bulk Head Pattern
- Retry Pattern
- Scatter Gather Pattern
- Bloom Filters Data Structure
What are Distributed Systems? #
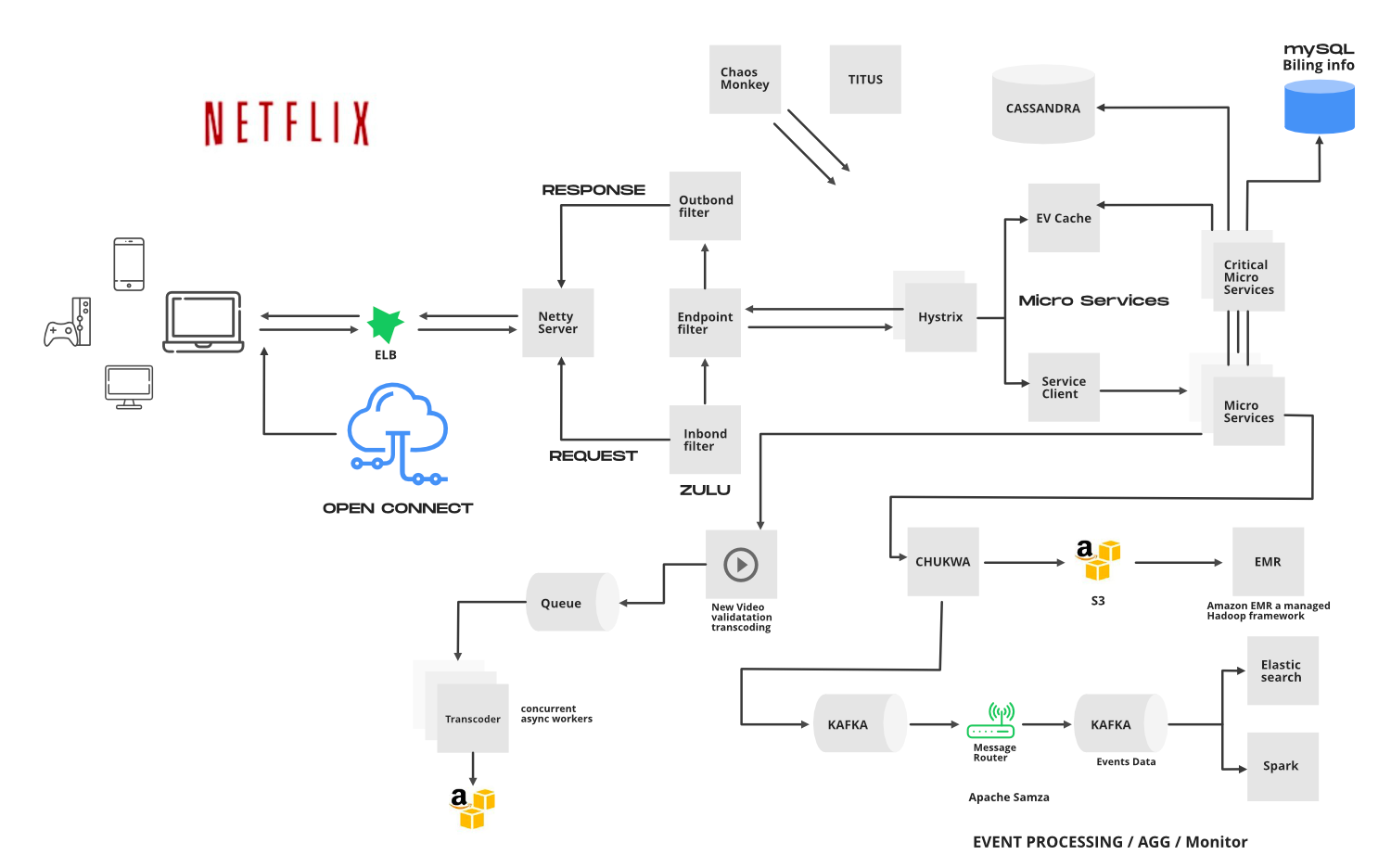
Netflix Architecture. Source
When I started my career, I worked as a front-end developer for an agency.
We used to get requests from clients and then we’d just build their site.
Back then I didn’t fully understand the architecture and infrastructure behind the stuff I was building.
Thinking back about it now, it wasn’t complicated at all.
We had one backend service written in PHP and Yii2 (PHP Framework) and a frontend written in JavaScript and React.
All of this was deployed to one server hosted in ps.kz (Kazakhstan Hosting Provider) and exposed to the internet using NGINX as a web server.
This architecture works for most projects. But once your application becomes more complex and popular, the cracks begin to show.
You get problems such as:
- Complexity – Codebase is too large and too complex for one person to mentally handle. It’s also hard to create new features and maintain old ones.
- Performance Issues – The popularity of your app caused it to have a lot of network traffic and it has proven to be too much for your single server. Because of that, the application has started to face performance issues.
- Inflexibility – Having a single codebase means that you are stuck with the technology stack that you began with. If you want to change it, then you will either have to rewrite the whole thing in another language or break up the app.
- Fragile System – Code being highly coupled together means that if any of the functionality breaks then the whole application will break. This leads to more downtime which will lose the business more money.
There are many ways to optimize a monolithic application, and it can go very far. Many big tech companies such as Netflix, Google, and Facebook (Meta) started off as monolithic applications because they’re easier to launch.
But they all began facing problems with monoliths at scale and had to find a way to fix it.
What did they do? They restructured their architectures. So instead of having a single super service that contained all the features of their business, they now had multiple independent services that talk to each other.
This is the basis of distributed systems.
Some people mistake distributed systems for microservices. And it’s true – microservices are a distributed system. But distributed systems do not always follow the microservice architecture.
So with that in mind, let’s come up with a proper definition for distributed systems:
A distributed system is a computing environment in which various components are spread across multiple computers (or other computing devices) on a network.
Common Challenges in Distributed Systems #
Distributed systems are by far much more complex than monolithic ones.
That’s why before migrating or starting a new project, you should ask the question:
Do I really need it?
If you decide that you do need a distributed system, then there are some common challenges you will face:
- Heterogeneity – Distributed systems allow us to use a wide range of different technologies. The problem lies in how we keep consistent communication between all the different services. Thus it is important to have common standards agreed upon and adopted to streamline the process.
- Scalability – Scaling is no easy task. There are many factors to keep in mind such as size, geography, and administration. There are many edge cases, each with their own pros and cons.
- Openness – Distributed systems are considered open if they can be extended and redeveloped.
- Transparency – Transparency refers to the distributed system’s ability to conceal its complexity and give off the appearance of a single system.
- Concurrency – Distributed systems allow multiple services to use shared resources. Problems may arise when multiple services attempt to access the same resources at the same time. We use concurrency control to ensure that the system remains in a stable state.
- Security – Security is comprised of three key components: availability, integrity, and confidentiality.
- Failure Handling – There are many reasons for errors in a distributed system (for example, software, network, hardware, and so on…). The most important thing is how we handle those errors in a graceful way so that the system can self-heal.
Yea, designing robust and scalable distributed systems is not easy.
But you are not alone. Other smart people have faced similar problems and offer common solutions which are called design patterns.
Let’s cover the most popular ones.
PS. We won’t only cover patterns, but anything that helps in distributed systems. This may include data structures, algorithms, common scenarios, etc…
Command and Query Responsibility Segregation (CQRS) Pattern #
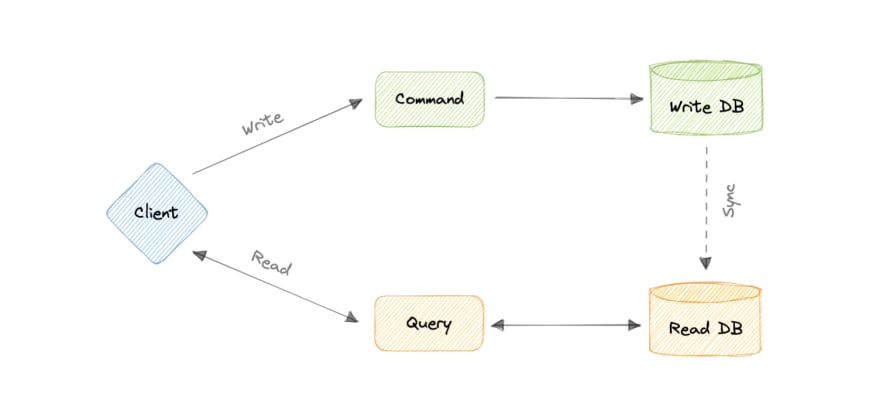
Imagine that you have an application with millions of users. You have multiple services that handle the backend, but as a single database.
The problem arises when you do reads and writes on this same database. Writes are a lot more expensive to compute than reads, and the system starts to suffer.
This is what the CQRS pattern solves.
It states that writes (commands) and reads (queries) should be separated. By separating writes and reads, we can allow developers to optimize each task separately.
For example, you might choose a high-performance database for write operations and a cache or search engine for read operations.
Pros #
- Code Simplification – Reduces system complexity by separating writes and reads.
- Resource Optimizations – Optimizes resource usage by having a separate database for writes and reads.
- Scalability – Improves scalability for reads as you can simply add more database replicas.
- Reduce Number of Errors – By limiting the entities that can modify shared data, we can reduce the chances of unexpected modifications of data.
Cons #
- Code Complexity – Adds code complexity by requiring developers to manage reads and writes separately.
- Increased Development Time – This can increase development time and cost (in the beginning only).
- Additional Infrastructure – This may require additional infrastructure to support separate read and write models.
- Increased Latency – It can cause increased latency when sending high-throughput queries.
Use Cases #
CQRS is best used when an application’s writes and reads have different performance requirements. But it is not always the best approach, and developers should carefully consider the pros and cons before adopting the pattern.
Here are some use cases that utilize the CQRS pattern:
- E-Commerce – Separate read models for product catalogs and recommendations, while the write side handles order processing and inventory management.
- Banks – Optimize read models for balance inquiries and reporting, while the write side handles transactions and calculations.
- Healthcare – CQRS can be used to optimize the reads for patient searches, medical record retrieval, and generating reports, while the write side manages data updates, scheduling, and treatment plans.
- Social Media –By applying CQRS, the read models can efficiently handle feed generation, personalized content recommendations, and user profile queries, while the write side handles content creation, updates, and engagement tracking.
Two-Phase Commit (2PC) Pattern #
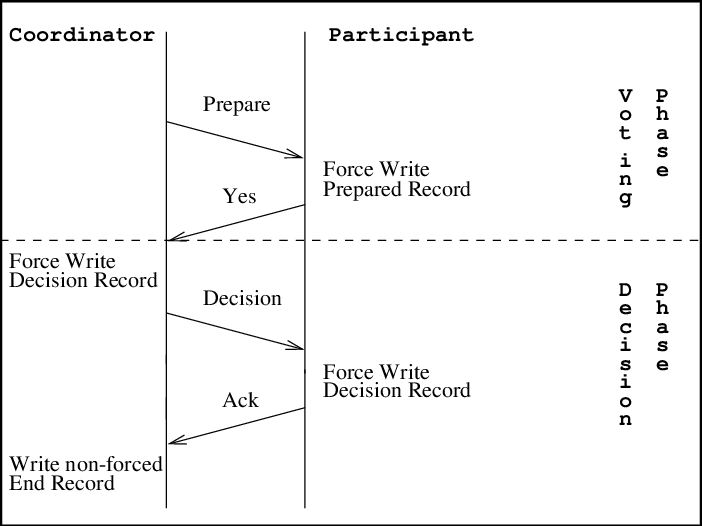
2PC solves the problem of data consistency. When you have multiple services talking to a relational database, it’s hard to keep the data consistent as one service can create a transaction while the other aborts it.
2PC is a protocol that ensures that all services commit or abort a transaction before it is completed.
It works in two phases. The first phase is the Prepare phase in which the transaction coordinator tells the service to prepare the data. Then comes the Commit phase, which signals the service to send the prepared data, and the transaction gets committed.
2PC systems make sure that all services are locked by default. This means that they can’t just write to the database.
While locked, the services complete the Prepare stage to get their data ready. Then the transaction coordinator checks each service one-by-one to see if they have any prepared data.
If they do, then the service gets unlocked and the data gets committed. If not, then the transaction coordinator moves on to another service.
2PC ensures that only one service can operate at a time, which makes the process more resistant and consistent than CQRS.
Pros #
- Data Consistency – Ensures data consistency in a distributed transaction environment.
- Fault Tolerance – Provides a mechanism to handle transaction failures and rollbacks.
Cons #
- Blocking – The protocol can introduce delays or blocking in the system, as it may have to wait for unresponsive participants or resolve network issues before proceeding with the transaction.
- Single point of failure – Reliance on a single coordinator introduces a potential point of failure. If the coordinator fails, the protocol may be disrupted, leading to transaction failures or delays.
- Performance overhead – The additional communication rounds and coordination steps in the protocol introduce overhead, which can impact the overall performance, especially in scenarios with many participants or high network latency.
- Lack of scalability – As the number of participants increases, the coordination and communication overhead also increase, potentially limiting the scalability of the protocol.
- Blocking during recovery – The protocol may introduce blocking during recovery until the failed participant is back online, impacting system availability and responsiveness.
Use Cases #
2PC is best used for systems that deal with important transaction operations that must be accurate.
Here are some use cases where the 2PC pattern would be beneficial:
- Distributed Databases – Coordinating transaction commits or aborts across multiple databases in a distributed database system.
- Financial Systems – Ensuring atomic and consistent transaction processing across banks, payment gateways, and financial institutions.
- E-commerce Platforms – Coordinating services like inventory management, payment processing, and order fulfillment for reliable and consistent transaction processing.
- Reservation Systems – Coordinating distributed resources and participants in reservation processes for consistency and atomicity.
- Distributed File Systems – Coordinating file operations across multiple nodes or servers in distributed file systems to maintain consistency.
Saga Pattern #
So let’s imagine that you have an e-commerce app that has three services, each with its own database.
You have an API for your merchants which is called /products to which you can add a product with all its information.
Whenever you create a product, you also have to create its price and meta-data. All three are managed in different services with different databases.
So, you implement the simple approach of:
Create product -> create price -> create meta-data
But what if you created a product but failed to create a price? How can one service know that there was a failed transaction of another service?
The saga pattern solves this problem.
There are two ways to implement sagas: orchestration and choreography.
Orchestration #
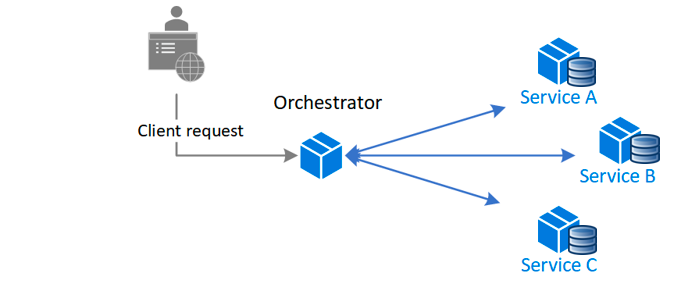
The first method is called Orchestration.
You have a central service that calls all the different services in the right order.
The central service makes sure that if there is a failure, it will know how to compensate for that by reverting transactions or logging the errors.
Pros #
- Suitable for complex transactions that involve multiple services or new services added over time.
- Suitable when there is control over every participant in the process and control over the flow of activities.
- Doesn’t introduce cyclical dependencies, because the orchestrator unilaterally depends on the saga participants.
- Services don’t need to know about commands for other services. There is a clear separation of concerns which reduces complexity.
Cons #
- Additional design complexity requires you to implement a coordination logic.
- If the orchestrator fails then the whole system fails.
When to Use Orchestration? #
You should consider using this pattern:
- If you need a centralized service that coordinates of the workflow.
- If you want a clear and centralized view of the workflow which makes it easier to understand and manage the overall system behavior.
- If you have complex and dynamic workflows that require a high degree of coordination and centralized control.
Choreography #
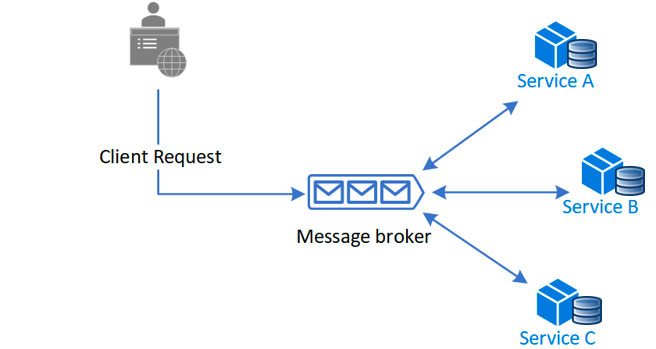
On the other hand, the Choreography method doesn’t use a central service. Instead, all communication between servers happens by events.
Services will react to events and will know what to do in case of success or failure.
So for our example above, when the user creates a product it will:
- Create an event called
product-created-successfully - Then the price service will react to the event by creating a price for the product and it will then create another event called
price-created-successfully - The same logic applies to the meta-data service.
Pros #
- Suitable for simple workflows that don’t require complex coordination logic.
- Simple to implement because it doesn’t require additional service implementation and maintenance.
- There is no single point of failure as responsibilities are distributed between the services.
Cons #
- Difficult to debug because it’s difficult to track which saga services listen to which commands.
- There’s a risk of cyclic dependency between Saga services because they have to consume each other’s commands.
- Integration testing is difficult because all services must be running to simulate a transaction.
When to Use Choreography: #
You should consider using this pattern if:
- The application needs to maintain data consistency across multiple microservices without tight coupling.
- There are long-lived transactions and you don’t want other microservices to be blocked if one microservice runs for a long time.
- You need to be able to roll back if an operation fails in the sequence.
Replicated Load-Balanced Services (RLBS) Pattern #
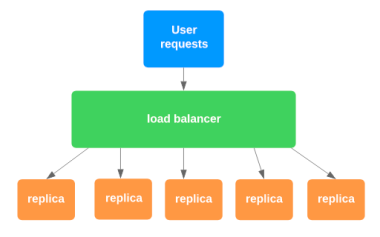
This is essentially a load balancer – I don’t know why they made it sound so intimidating.
A load balancer is software or hardware that distributes network traffic equally between a set of resources.
But that’s not always the case – it can also route different routes to different services.
So for example:
/frontendgoes to the front-end service./apigoes to the backend service.
Pros #
- Performance – Load balancing distributes the workload evenly across multiple resources, preventing any single resource from becoming overloaded. This leads to improved response times, reduced latency, and better overall performance for users or clients accessing the system.
- Scalability – Load balancing allows you to scale horizontally, meaning that instead of getting more powerful servers, you can get more servers.
- High availability – As said above, load balancing allows us to vertically scale which means we have multiple servers. If one server fails then the load balancer will detect that and traffic can be redirected to other working servers.
- Better resource utilization – Load balancing helps to optimize resource utilization by distributing traffic evenly across multiple servers or resources. This ensures that each server or resource is used efficiently, helping to reduce costs and maximize performance.
Cons #
- Complexity – Implementing and configuring load balancing can be complicated especially for large scale systems.
- Single Point of Failure – While load balancers enhance system availability, they can also become a single point of failure. If the load balancer itself fails, it can cause a disruption in service for all resources behind it.
- Increased Overhead –Load balancers computations are not free, if they are not controlled then they can become a bottleneck to the entire system.
- Session Handling Challenges – Load balancing stateful applications is a bit tricky as you need to maintain sessions. It requires additional mechanisms such as sticky sessions or session synchronization, which adds complexity.
When to use load balancing #
A load balancer is mainly used when:
- You have a high traffic website and you want to spread the load so that your servers don’t fry.
- You have users from all over the world and want to serve them data from their closest location. You could have a server in Asia and another in Europe. The load balancer would then route all users from Asia to the Asian server and European users to the Europe server.
- You have a service orientated architecture with API’s corresponding to different services. Load balancing can be used as a simple API gateway.
I’ve written a bunch of articles on load balancing, so feel free to check them out.
- How to set up NGINX load balancing: a step-by-step guide
- Load balancing in Kubernetes: a step-by-step guide
- Load balancing 101: How it works and why it matters for your platform
Sharded Services Pattern #
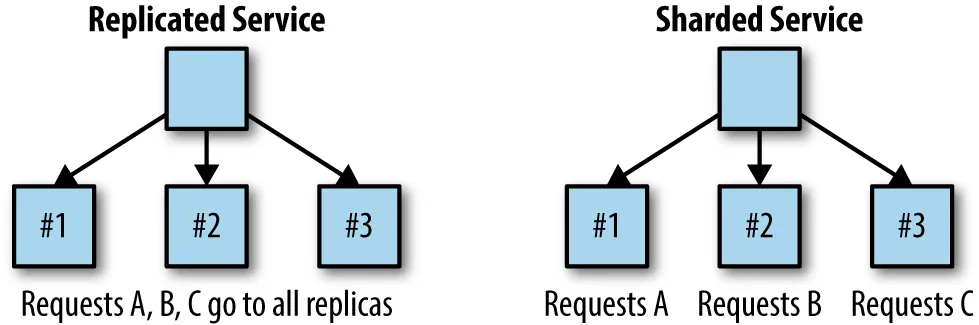
In the previous section, we talked about replicated services. Any request can be processed by any of the services. This is because they are replicas of one another.
This is good for stateless services. But what if you have a stateful service? Then a sharded approach would be more appropriate.
Sharded service only accepts certain kinds of requests.
For example, you may have one shard service accept all caching requests while another shard service accepts high-priority requests.
But, how do we implement this? #
Well, if we are strictly talking about application services then you could go with the service oriented architecture approach. You could have multiple services developed and deployed independently.
Then you could use a load balancer to route requests by URL path to the appropriate service.
PS. Sharding is not only used for application services but can be used for databases, caches, CDNs, etc…
Pros: #
- Scalability – Sharding allows you to distribute load across multiple nodes or servers, thus enabling horizontal scaling. As your workload increases, you can just add more shards.
- Performance – A single node doesn’t have to handle all requests especially if it is computationally heavy. Each node can take in a subset of requests, improving the systems performance.
- Cost-effectiveness – Sharding can be a cost-effective solution for scaling your system. Instead of investing in a single, high-capacity server, you can use commodity hardware and distribute the workload across multiple, less expensive servers.
- Fault isolation – Sharding provides a level of fault isolation. If one shard or node fails, the remaining shards can continue serving requests.
Cons: #
- Complexity – Sharding is not easy to implement. It requires careful planning and design to handle data distribution, consistency, and query coordination.
- Operational overhead – Managing a sharded system involves additional operational tasks such as monitoring, maintenance, and backup, which can require more resources and expertise.
Use Cases #
The Sharded Services Pattern is typically used in the following scenarios:
- Performance Requirements – If your system is dealing with large data volumes or high read/write workloads that a single server cannot handle, sharding can distribute the workload across multiple shards. This enables parallel processing and improving overall performance.
- Scalability requirements – When you anticipate the need for horizontal scalability in the future, sharding can be implemented from the beginning to provide the flexibility to add more shards and scale the system as the workload grows.
- Cost considerations – If vertical scaling (upgrading to more powerful hardware) becomes cost-prohibitive, sharding offers a cost-effective alternative by distributing the workload across multiple, less expensive servers or nodes.
- Geographical distribution – Sharding can be beneficial when you need to distribute data across different geographical locations or data centers, allowing for improved performance and reduced latency for users in different regions.
But keep in mind that there must be careful considerations when sharding your services as it is very complex and expensive to implement and revert.
Sidecar Pattern #
In a service-oriented architecture, you might have a lot of common functionalities – things such as error handling, logging, monitoring, and configuration.
In the past, there were two ways to solve this problem:
Implement common functionalities within the service #
The problem with this approach is that the utilities are tightly linked and run within the same process by making efficient use of the shared resources. This makes the components interdependent.
If one functionality fails then this can lead to another functionality failing or the whole service failing.
Implement common functionalities in a separate service #
This may seem a good approach because the utilities can be implemented in any language and it does not share resources with other services.
The downsides are that it adds latency to the application when we deploy two services on different containers, and it adds complexity in terms of hosting, deployment, and management.
How can we do it better? #
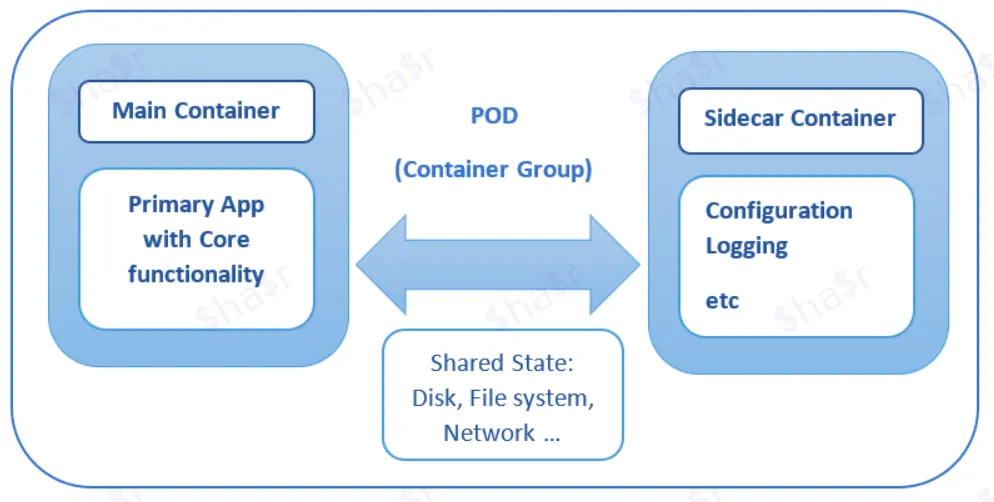
One method is using the side-car pattern. It states that a container should only address a single concern and do it well.
So to do that, we have a single node (virtual or physical machine) with two containers.
The first is the application container which contains the business logic. The second container, usually called the sidecar, is used to extend/enhance the functionality of the application container.
Now you might ask, “But, how is this useful?”
You should keep in mind that the sidecar service runs in the same node as the application container. So they share the same resources (like filesystem, memory, network, and so on…)
An example #
Let’s say you have a legacy application that generates logs and saves them in a volume (persisted data) and you want to extract them into an external platform such as ELK.
One way to do this is just extending the main application. But that’s difficult due to the messy code.
So you decide to go with the sidecar method and develop a utility service that:
- Captures the logs from the volume.
- Transfers the logs into Elastic.
The architecture of the node would look something like this:
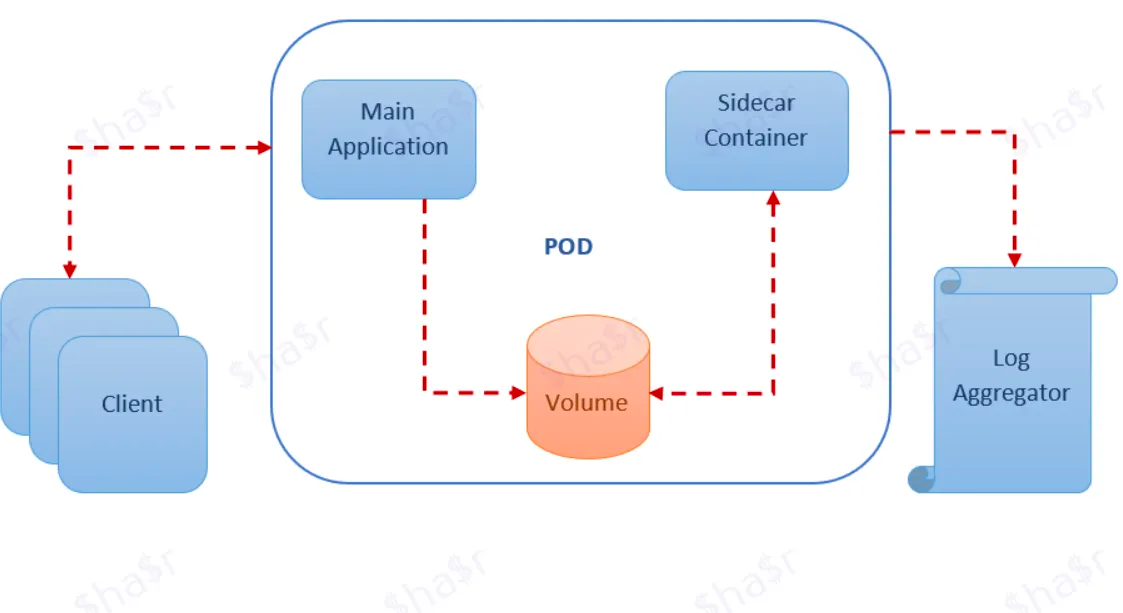
Hooray, you haven’t changed any code in the application and you extended its functionality by plugging in a sidecar.
Heck, you can even plug this log aggregator sidecar into other applications.
Pros: #
- Modularity – Sidecar allows you to develop and maintain utility functions independently.
- Scalability – If there is too much load on the sidecar, you can easily horizontally scale it by adding more containers.
- Isolation – The sidecar is isolated from the main application, providing an additional layer of security.
Cons: #
- Complexity – It requires extra management of multiple containers and their dependencies.
- Resource overhead – Because we have an extra container, this can increase the overall resource usage of the application.
- Coordination – The sidecar must be coordinated in a way that it works correctly with the main application which increases complexity.
- Debugging – Debugging is more difficult with the sidecar pattern, as it requires tracing the interactions between the main application and the sidecar.
Use Cases #
The sidecar pattern is useful when you want to add additional functionality to the application without touching the core business logic code.
By deploying the sidecar, the core logic can remain lightweight and focus on its primary task while the sidecar can handle additional functionality.
If need be, you can reuse the sidecar for other applications too.
Now that we know when to use this pattern, let’s look at some use cases where it is beneficial:
- Logging and Monitoring – The sidecar container collects logs and metrics from the main container, providing centralized storage and real-time monitoring for improved observability.
- Caching – The sidecar container caches frequently accessed data or responses, enhancing performance by reducing the need for repeated requests to external services.
- Service Discovery and Load Balancing – The sidecar container registers the main container with a service discovery system, enabling load balancing and fault tolerance across multiple instances of the main container.
- Security and Authentication – The sidecar container handles authentication tasks, offloading responsibilities like OAuth, JWT verification, or certificate management from the main container.
- Data Transformation and Integration – The sidecar container performs data transformation and integration tasks, facilitating seamless communication and synchronization between the main container and external systems.
- Proxy and Gateway – The sidecar container acts as a proxy or gateway, providing functionalities like rate limiting, SSL termination, or protocol translation for enhanced communication capabilities.
- Performance Optimization – The sidecar container handles CPU-intensive tasks or background processes, optimizing resource usage and improving the main container’s performance.
Write-Ahead Log Technique #
Imagine this: you are working on a service that is connected to a database with sensitive user information.
One day, the server crashes. Your database crashes. All the data is gone, apart from the backups.
You sync the database with the backup, but the backup is not up to date. It’s 1 day old. You sit and cry in the corner.
Well thankfully, that will most likely never happen.
Because most databases have something called a write-ahead log (WAL).
What is a write-ahead log? #
A write-ahead log is a popular technique used to preserve:
- Atomicity – Every transaction is treated as a single unit. Either the entire transaction is executed, or none of it is executed. This ensures that the data does not get corrupted or lost.
- Durability – Ensures that the data will not be lost, even in an event of a system failure.
But how does it work? #
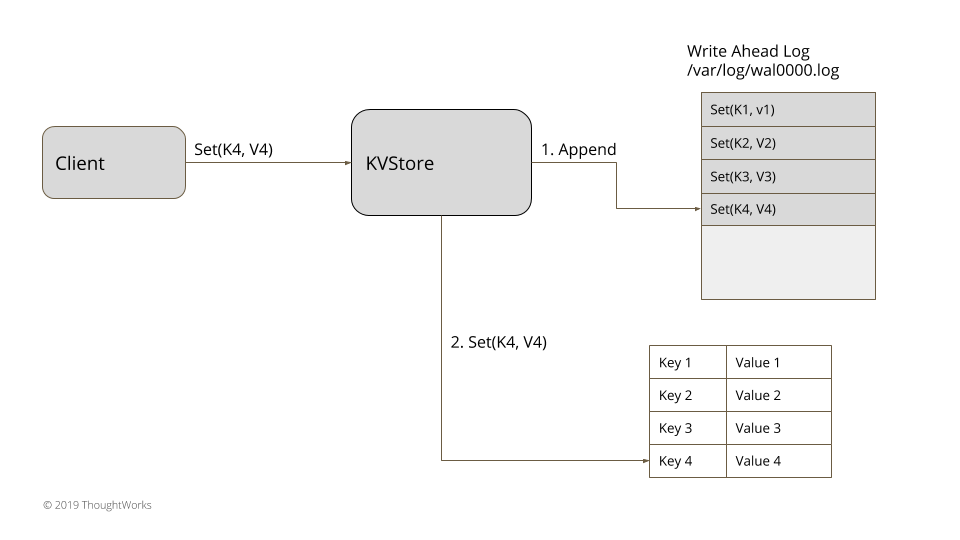
A WAL stores every change you made onto a file on a hard disk.
So for example, let’s say you created your own in-memory database called KVStore. In case of system failure, you want:
- Data to not be lost.
- Data to be recovered onto memory.
So you decide to implement a write-ahead log.
Every time you do any transaction (SET or REMOVE), the command will be logged into a file on the hard disk. This allows us to recover the data in case of system failure. The memory will be flushed, but the log is still stored in the hard drive.
The overall architecture would look something like this:
It’s not all sunshine and rainbows #
As useful as it is, WAL is not easy to implement. There are many nuances, but the most common ones are:
Performance #
If you use standard file-handling libraries in most programming languages, you would most likely “flush” the file onto the hard disk.
Flushing every log will give you a strong guarantee of durability. But this severely limits performance and can quickly become a bottleneck.
You might ask, “why don’t we delay flushing or do it asynchronously?”
Well, this might improve performance but at the risk of losing entries from the log if the server crashes before entries are flushed.
The best practice here is to implement techniques like Batching, to limit the impact of the flush operation.
Data Corruption #
The other consideration is that we have to make sure that corrupted log files are detected.
To handle this, save log files via CRC (Cyclic Redundancy Check) records, which validates the files when read.
Storage #
Single Log files can be difficult to manage and can consume all the available storage.
To handle this issue, use techniques like:
- Segmented Log – Split the single log into multiple segments.
- Low-Water Mark – This technique tells us which portion of the logs can be safely discarded.
These two techniques are used together as they both complement each other.
Duplicate Entries #
WALs are append-only, meaning that you can only add data. Because of this behavior, we might have duplicate entries. So when the log is applied, it needs to make sure that the duplicates are ignored.
One way to solve this is to use a hashmap, where updates to the same key are idempotent. If not, then there needs to be a mechanism to mark each transaction with a unique identifier and detect duplicates.
Use Cases #
Overall WALs are mostly used in databases but can be beneficial in other areas:
Write-ahead logs (WALs) are widely used in various systems and databases. Here are some common use cases for write-ahead logs:
- File Systems – File systems can employ write-ahead logging to maintain data consistency. By logging changes before applying them to the file system, WALs allow for crash recovery and help prevent data corruption in case of system failures.
- Message Queues and Event Sourcing – Write-ahead logs are often used in message queues and event sourcing architectures. The logs serve as a reliable and ordered record of events, allowing for reliable message delivery, event replay, and system state restoration.
- Distributed Systems – Distributed systems that need to maintain consistency across multiple nodes can benefit from write-ahead logs. By coordinating log replication and replay, WALs help synchronize data updates and ensure consistency in distributed environments.
Split-Brain Pattern #
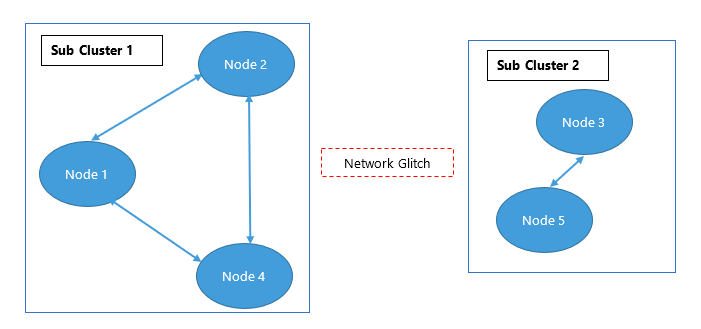
That’s definitely an interesting name, isn’t it? It might make you think of the two halves of the brain.
Well, it is actually somewhat similar.
A split brain in distributed systems happens when nodes in a distributed system become disconnected from each other but still continue to operate.
Split brain? Nodes working independently when they should work together? Sound similar? I hope so.
Anyways, the biggest problem with this is that it causes:
- Data Inconsistency
- Competing for resources
This will usually shut the cluster off while developers try to fix things. This causes downtime which makes the business lose money.
What’s the fix? #
One fix is using a generational number. Every time a leader is elected, the generation number gets incremented.
For example, if the old leader had a generational number of one, then the second leader will have a generational number of two.
The generation number is included in every request, and now clients can just trust the leader with the highest number.
But keep in mind that the generational number must be persisted on disk.
One way to do that is using a Write Ahead Log. See, things are connected to each other.
This solution is categorized as a leader election but there are others:
- Quorum-based Consensus – Use algorithms like Raft or Paxos to ensure that only a majority of nodes can make decisions, preventing conflicting decisions in a split brain scenario.
- Network Partition Detection – Use monitoring techniques or distributed failure detectors to identify network partitions and take appropriate actions.
- Automatic Reconciliation – Implement mechanisms to automatically resolve conflicts and ensure data consistency once a split brain is resolved, such as merging conflicting changes or using timestamps or vector clocks.
- Application-level Solutions – Design the application to tolerate split brain scenarios by employing eventual consistency models, conflict-free data structures, or CRDTs.
- Manual Intervention –In some cases, manual intervention may be required to resolve split brain scenarios, involving human decision-making or administrative actions to determine the correct system state and perform data reconciliation.
Pros #
- Data Consistency – Implementing a fix ensures that shared data remains consistent across the distributed system.
- System Stability – Resolving split brain scenarios promotes system stability by avoiding conflicting operations and maintaining coherent behavior.
Cons #
- Increased Complexity – Fixing split brain scenarios adds complexity to the system due to the intricate logic and mechanisms required.
- Performance Overhead – Split brain resolution mechanisms may impact system performance and latency due to additional processing and communication requirements.
- Higher Resource Utilization – Addressing split brain scenarios may require allocating more resources, potentially increasing costs.
- Increased Failure Surface – Introducing split brain resolution mechanisms may inadvertently introduce new failure modes or vulnerabilities.
- Configuration and Tuning Complexity – Implementing a fix requires careful configuration and ongoing maintenance to ensure optimal behavior in different scenarios.
Hinted Handoff Pattern #
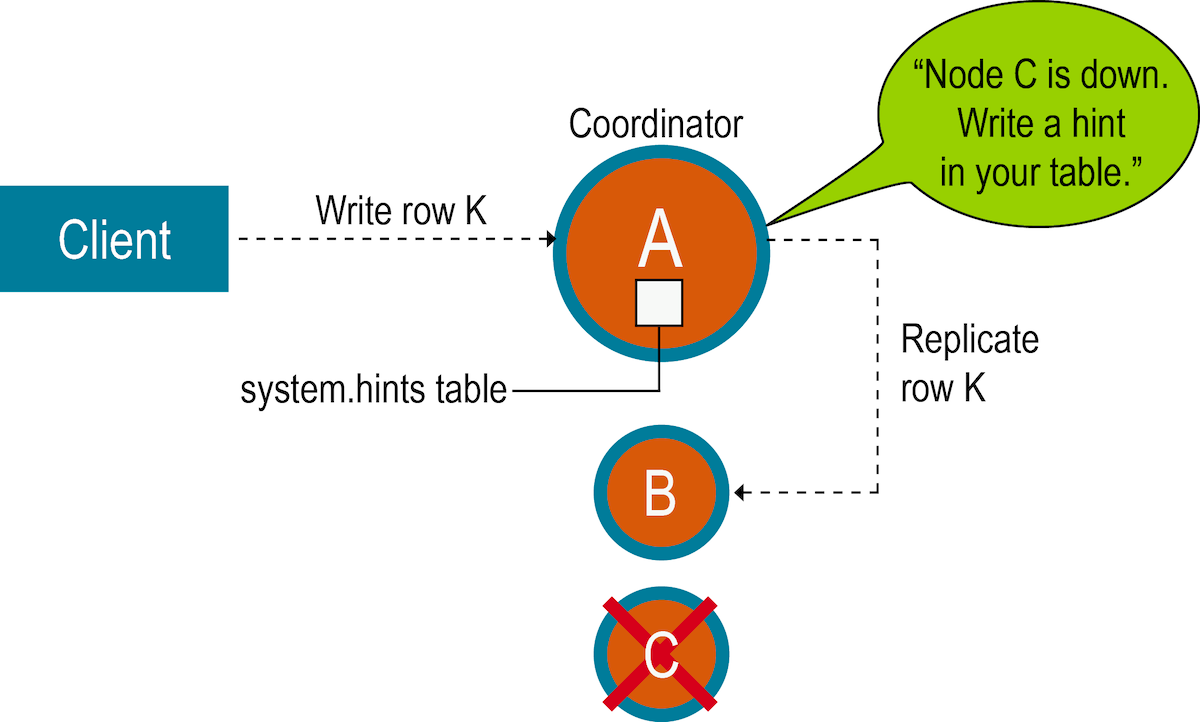
The Hinted Handoff technique makes sure that you have:
- Fault Tolerance – The ability of the system to continue working even if one or more components fail.
- Availability of Data – Ability to access and modify the data at any given time.
What problem does it solve? #
Imagine you have a bank service that communicates with a node that has three replicas. None of the nodes are leaders, so the architecture is leaderless.
You send a request to update the customer’s balance to $100. You send this to all the replicas.
The request is successful for the first two replicas but the last one is down. After a few seconds, the replica that was down got back up again but it has the old data.
How do we fix this issue? #
The hinted handoff technique says that when a node for a particular data goes offline, then the other nodes of the system will temporarily store updates or modifications intended for the unavailable node.
Hence the name “hints”.
So when the unavailable node comes back alive, it can retrieve the hints and apply them.
So the process goes like this:
- Detection – When a node fails, other nodes detect this failure and mark that node as unavailable.
- Hint Generation – When a node receives a request to send to the unavailable node, it will store it locally, usually to a file on the disk.
- Hint Delivery – When the available node goes back online, it sends a message to the other nodes requesting any hints that were made while it was offline. The other nodes send the hints and the node applies them.
By using this technique we ensure our data is consistent and available even when nodes fail or become temporarily unavailable.
Pros #
- Improved data availability – Hinted handoff ensures data remains accessible during temporary node failures by transferring responsibilities to other nodes.
- Data consistency – Hinted handoff helps maintain data consistency by synchronizing the failed node with others when it recovers.
- Reduced latency – Hinted handoff minimizes the impact of node failures on system performance, routing requests to alternative nodes and reducing latency.
- Scalability – Hinted handoff enables dynamic redistribution of data responsibilities, allowing the system to handle increased workloads and node changes.
Cons #
- Increased complexity – Implementing hinted handoff adds complexity to the system, making development, debugging, and maintenance more challenging.
- Storage overhead – Hinted handoff requires storing additional metadata, incurring storage overhead to track handoff status.
- Potential data staleness – After a failure, recovered nodes may have temporarily stale data until synchronization occurs, leading to potential inconsistencies.
- Increased network traffic – Hinted handoff involves transferring data responsibilities, resulting in increased network traffic and potential impact on network performance.
Use Cases #
Hinted handoff is typically implemented in distributed database systems or distributed storage systems where data availability and consistency are crucial.
Here are some scenarios where implementing hinted handoff is beneficial:
- Cloud storage systems – Hinted handoff enables seamless redirection of client requests to available nodes in cloud storage systems when a node becomes temporarily unavailable.
- Messaging systems – Hinted handoff allows distributed messaging systems to route messages to other active brokers when a broker node fails, ensuring message delivery and system operability.
- Distributed file systems – Hinted handoff in distributed file systems allows the temporary transfer of data responsibilities to other nodes when a data node fails, ensuring data availability and uninterrupted read/write operations.
- Content delivery networks (CDNs) – Hinted handoff in CDNs facilitates the redirection of content delivery requests to other servers in the network when a server becomes temporarily unavailable, ensuring continuous content delivery to users.
Read Repair Pattern #
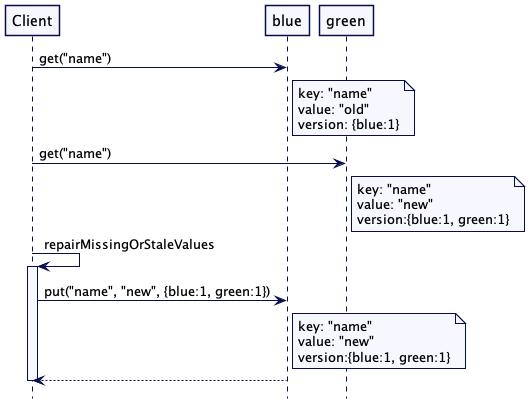
In a distributed system, you can have data partitioned into multiple nodes.
This introduces a new challenge where we have to keep the data consistent in all nodes.
For example, if you update data on node A, the changes might not be immediately propagated to other nodes due to all sorts of reasons.
So we use the “read repair” pattern #
When a client reads a piece of data from a node, that node will check if the data is the latest. If not, then it receives the latest data from another node.
Once it receives the latest data, it will update the node with the old data with the new data. Hence the “repair”.
But this is done on the application side #
Doing things on the application side is pretty flexible as you can have your own custom logic per service but it increases complexity and development time.
Thankfully, there are three other methods of implementing read repair:
- Write-Based Read Repair – Proactively update multiple replicas or nodes with the latest data during write operations.
- Background Repair – Schedule periodic background repair processes to scan and repair inconsistencies in the database.
- Database-Specific Read Repair – Leverage built-in read repair mechanisms or conflict resolution features provided by the database.
Pros #
- Data Consistency – Read repair maintains data consistency by automatically detecting and correcting inconsistencies between replicas or nodes.
- Improved User Experience – Read repair provides reliable and accurate data, enhancing the user experience by reducing conflicting or outdated information.
- Fault Tolerance – Read repair increases system resilience by addressing data inconsistencies and reducing the risk of cascading failures.
- Performance Optimization – Read repair improves performance by minimizing the need for separate repair processes and distributing the repair workload.
- Simplified Development – Read repair automates consistency checks, simplifying application development.
Cons #
- Increased Complexity – Implementing read repair adds complexity to system design, development, and maintenance efforts.
- Performance Overhead – Read repair may introduce additional latency and computational overhead, impacting overall system performance.
- Risk of Amplifying Failures – Incorrect implementation of read repair can propagate inconsistencies or amplify failures.
- Scalability Challenges – Coordinating repairs in large-scale systems can be challenging, impacting performance and scalability.
- Compatibility and Portability – Read repair mechanisms may be specific to certain databases or technologies, limiting compatibility and portability.
Use Cases #
Read repair can be beneficial in various scenarios where maintaining data consistency across replicas or nodes is crucial.
Here are some situations where you should consider using read repair:
- Distributed Database Systems – Use read repair in distributed database systems where data is replicated across multiple nodes or replicas to ensure data consistency.
- High Data Consistency Requirements – Implement read repair when your application requires a high level of data consistency, such as in financial systems, collaborative editing platforms, or real-time analytics.
- Read-Heavy Workloads – Consider read repair for read-heavy workloads to detect and reconcile inconsistencies during read operations, improving performance by reducing the need for separate repair processes.
- Systems with Network Delays or Failures – Use read repair in environments with network delays or occasional node failures to automatically detect and correct data inconsistencies caused by these issues.
Service Registry Pattern #
When you are working with a distributed system, you will have services that have instances that can scale up or down.
One service can have ten instances at one time and two at another time.
The IP addresses of these instances get created dynamically. Problems arise here.
Imagine that you have a client and it wants to talk to a service. How will it know the IP address of the service if IP addresses are dynamically created?
The answer is a service registry.
What the heck is that? #
A service registry is usually a separate service that runs that keeps information about available instances and their locations.
But how does the service registry know all this information?
When we create an instance of any of our services, we register ourselves to the service registry with our name, IP address, and port number.
The service registry then stores this information in its data store.
When a client needs to connect to a service, it queries the service registry to obtain the necessary information for connecting to the service.
Now that we know what a service registry is, let’s talk about the patterns of service discovery.
Client Side Discovery #
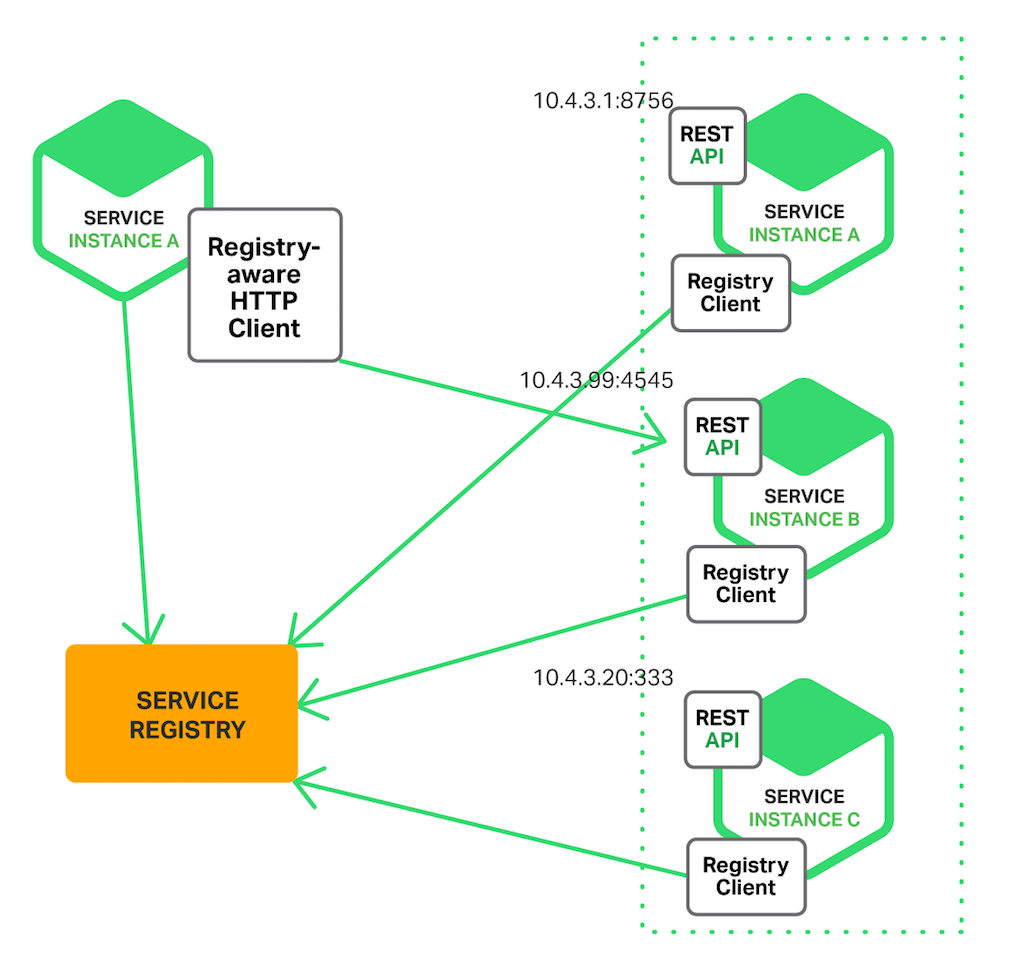
The first and easiest way is for the client to call the service registry and get information about all the available instances of a service.
This approach works well when you want to:
- Have something simple and straightforward.
- Have the client-side make the decisions about which instances to call.
But the significant drawback here is that it couples the client with the service registry.
So you must implement client-side discovery logic for every programming language and framework that your service uses.
Server Side Discovery #
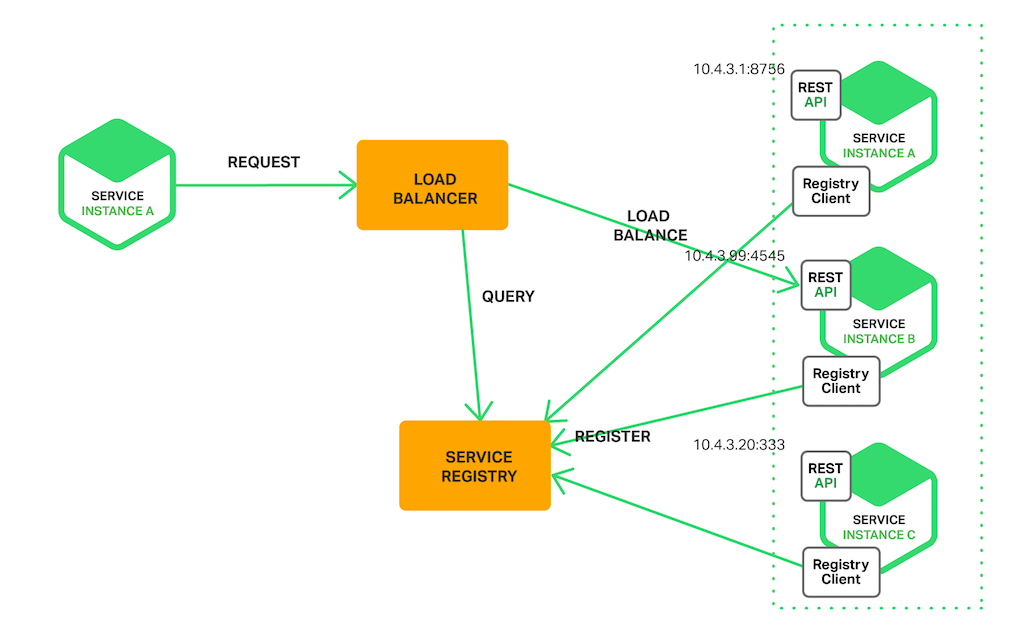
On the other hand, the server-side discovery forces the client to make the request via a load balancer.
If you don’t know what a load balancer is, feel free to check out my other comprehensive article on it.
The load balancer will call the service registry and routes the request to the specific instance.
Server-side discovery has the following benefits:
- Abstracting the details of the service registry to the load balancer means that the client can simply make a request to the load balancer.
- It’s built-in in most popular providers such as AWS ELB (Elastic Load Balancer).
The only downside is that you have another component (service registry) in your infrastructure that you have to maintain.
Circuit Breaker Pattern #
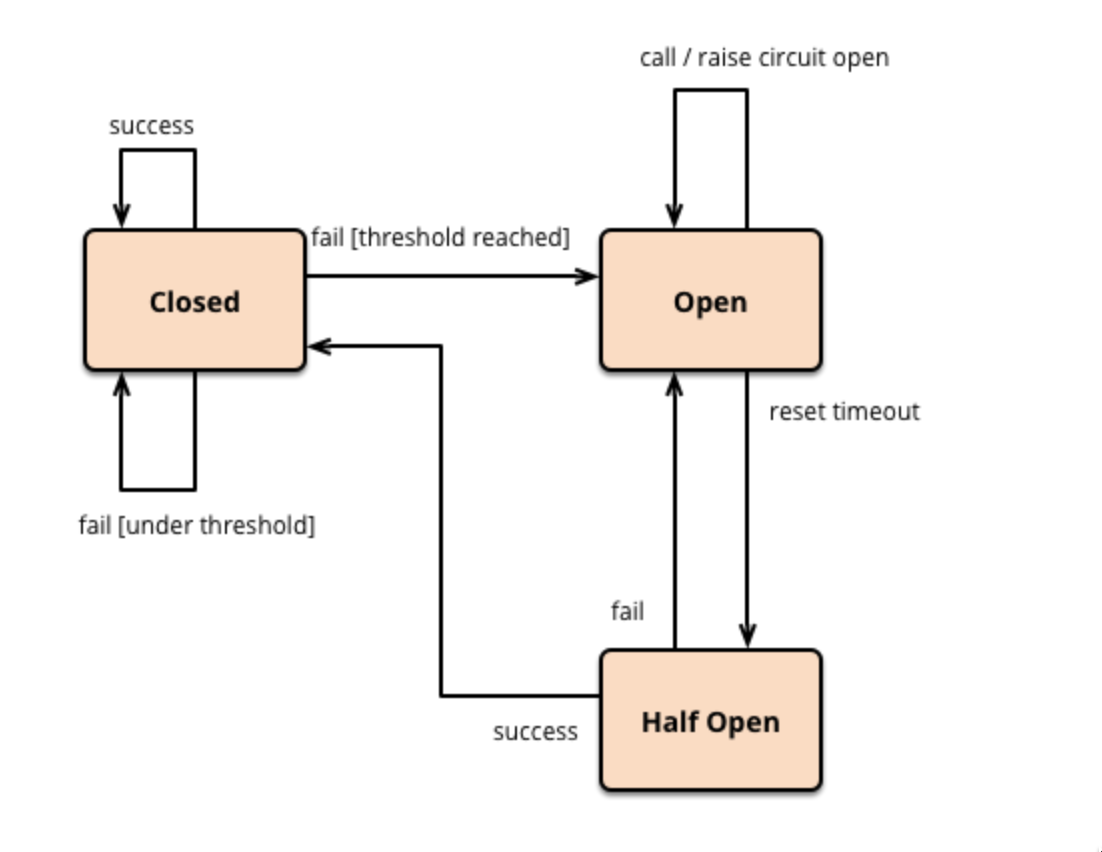
Let’s say you have three services, A, B, and C. They all call each other sequentially – A calls B, which calls C.
All goes well as long as the services work. But what if one of the services is down Then the other services would fail. If service C is down, then B and A would be down, too.
How do we fix this? #
We use the circuit breaker pattern which acts as a middleware between two services.
It monitors the state of the second service and, in case of failure or unresponsiveness, stops the requests to the service and returns a fallback response or error message to the component.
The middleware has three states:
- Closed – The service can communicate with the second service normally.
- Open – When the middleware detects a certain number of consecutive failures then it transitions to the open state, and all requests to the service are immediately blocked.
- Half Open – After a certain period of time, the middleware transitions to a half-open state which allows a limited number of requests to be sent to the second service. If successful, then the middleware transitions to a closed state otherwise it will transition to an open state.
Overall, the circuit breaker pattern increases resilience by providing a fallback mechanism and reducing the load on a failed service.
It also provides insight into the status of a service which helps us identify failures more quickly.
Pros #
- Fault tolerance – Circuit breakers enhance system stability by protecting against cascading failures and reducing the impact of unavailable or error-prone dependencies.
- Fail-fast mechanism – Circuit breakers quickly detect failures, allowing for faster recovery and reducing latency by avoiding waiting for failed requests to complete.
- Graceful degradation – Circuit breakers enable the system to gracefully degrade functionality by providing alternative responses or fallback mechanisms during failures.
- Load distribution – Circuit breakers can balance the load across available resources during high traffic or when a service is experiencing issues.
Cons #
- Increased complexity – Implementing a circuit breaker adds complexity to the system, impacting development, testing, and maintenance efforts.
- Overhead and latency – Circuit breakers introduce processing overhead and latency as requests are intercepted and evaluated against circuit states.
- False positives – Circuit breakers can mistakenly block requests even when the dependency is available, leading to false positives and impacting system availability and performance.
- Dependency on monitoring – Circuit breakers rely on accurate monitoring and health checks, and if these are unreliable, the effectiveness of the circuit breaker may be compromised.
- Limited control over remote services – Circuit breakers provide protection but lack direct control over underlying services, requiring external intervention for resolving certain issues.
Use Cases #
The circuit breaker pattern is beneficial in specific scenarios where a system relies on remote services or external dependencies.
Here are some situations where it is recommended to use the circuit breaker pattern:
- Distributed systems – When building distributed systems that communicate with multiple services or external APIs, the circuit breaker pattern helps improve fault tolerance and resilience by mitigating the impact of failures in those dependencies.
- Unreliable or intermittent services – If you are integrating with services or dependencies that are known to be unreliable or have intermittent availability, implementing a circuit breaker can protect your system from prolonged delays or failures caused by those dependencies.
- Microservices architecture – In a microservices architecture, where individual services have their own dependencies, implementing circuit breakers can prevent cascading failures across services and enable graceful degradation of functionality during failures.
- High-traffic scenarios – In situations where the system experiences high traffic or load, circuit breakers can help distribute the load efficiently by redirecting requests to alternative services or providing fallback responses, thereby maintaining system stability and performance.
- Resilient and responsive systems – The circuit breaker pattern is useful when you want to build systems that are resilient and responsive to failures. It allows the system to quickly detect and recover from issues, reducing the impact on users and ensuring a smoother user experience.
Leader Election Pattern #
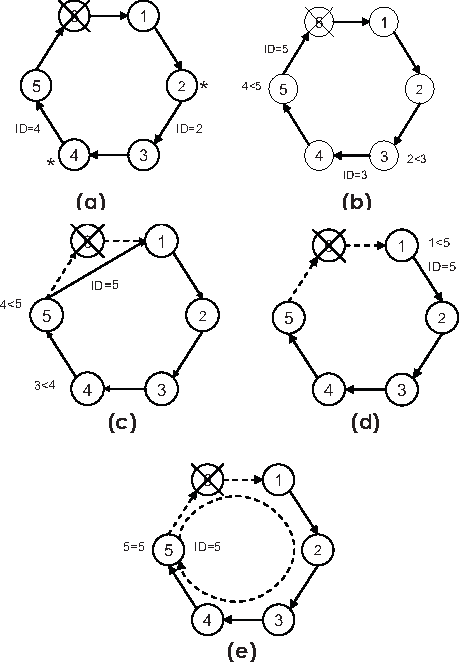
The leader election pattern is a pattern that gives a single thing (process, node, thread, object) superpowers in a distributed system.
This pattern is used to ensure that a group of nodes can coordinate effectively and efficiently.
So when you have three or five nodes performing similar tasks such as data processing or maintaining a shared resource, you don’t want them to conflict with one another (that is, contesting for resources or interfering with each other’s work).
Elect one leader that coordinates everything #
The leader will be responsible for critical decisions or distributing workloads among the other processes.
Any node can be a leader, so we should be careful when we elect them. We don’t want two leaders at the same time.
So we must have a good system for selecting a leader. It must be robust, which means it has to cope with network outages or node failures.
How to select a leader #
One algorithm named Bully assigns every node with a unique identifier. The node with the highest identifier initially is considered the leader.
If a low-ranked node detects that the leader has failed, it sends a signal to all the other high-ranked nodes to take over. If none of them respond then the node will make itself the leader.
Another popular algorithm is called the Ring algorithm. Each node is arranged in a logical ring. The node with the highest identifier is initialized as a ring.
If a lower-ranked node detects that the ring has failed, then it will request all the other nodes to update their leader to the next highest node.
Both of the above algorithms assume that every node can be uniquely identified.
Pros #
- Coordination – Leader election allows for better organization and coordination in distributed systems by establishing a centralized point of control.
- Task Assignment – The leader can efficiently allocate and distribute tasks among nodes, optimizing resource utilization and workload balancing.
- Fault Tolerance – Leader election ensures system resilience by promptly electing a new leader if the current one fails, minimizing disruptions.
- Consistency and Order – The leader maintains consistent operations and enforces the proper order of tasks in distributed systems, ensuring coherence.
Cons #
- Overhead and Complexity – Leader election introduces additional complexity and communication overhead, increasing network traffic and computational requirements.
- Single Point of Failure – Dependency on a single leader can lead to system disruptions if the leader fails or becomes unavailable.
- Election Algorithms – Implementing and selecting appropriate leader election algorithms can be challenging due to varying trade-offs in performance, fault tolerance, and scalability.
- Sensitivity to Network Conditions – Leader election algorithms can be sensitive to network conditions, potentially impacting accuracy and efficiency in cases of latency, packet loss, or network partitions.
Use Cases #
- Distributed Computing – In distributed computing systems, leader election is crucial for coordinating and synchronizing the activities of multiple nodes. It enables the selection of a leader responsible for distributing tasks, maintaining consistency, and ensuring efficient resource utilization.
- Consensus Algorithms – Leader election is a fundamental component of consensus algorithms such as Paxos and Raft. These algorithms rely on electing a leader to achieve agreement among distributed nodes on the state or order of operations.
- High Availability Systems – Leader election is employed in systems that require high availability and fault tolerance. By quickly electing a new leader when the current one fails, these systems can ensure uninterrupted operations and mitigate the impact of failures.
- Load Balancing – In load balancing scenarios, leader election can be used to select a leader node responsible for distributing incoming requests among multiple server nodes. This helps in optimizing resource utilization and evenly distributing the workload.
- Master-Slave Database Replication – In database replication setups, leader election is used to determine the master node responsible for accepting write operations. The elected master coordinates data synchronization with slave nodes, ensuring consistency across the replica set.
- Distributed File Systems – Leader election is often employed in distributed file systems, such as Apache Hadoop’s HDFS. It helps in maintaining metadata consistency and enables efficient file access and storage management across a cluster of nodes.
Bulk Head Pattern #
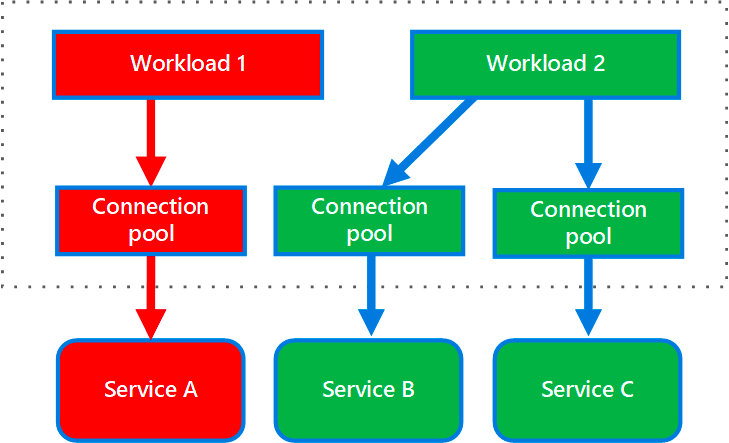
Things fail for all sorts of reasons in a distributed system. This is why we need to make sure our systems are resilient in case of failures.
One way to improve that is to use the bulkhead pattern.
So let’s say we have two services, A and B.
Some requests of A depend on B. But the issue is that service B is pretty slow which makes A slow and blocks its threads. This makes all requests to A slow, even the ones which don’t depend on B.
The bulkhead pattern solves that by allocating a specific amount of threads for requests to B. This prevents A from consuming all threads due to B.
Pros #
- Fault isolation – The bulkhead pattern contains failures within individual services, minimizing their impact on the overall system.
- Scalability – Services can be independently scaled, allowing allocation of resources where needed without affecting the entire system.
- Performance optimization – Specific services can receive performance optimizations independently, ensuring efficient operation.
- Development agility – Code modularity and separation of concerns facilitate parallel development efforts.
Cons #
- Complexity – Implementing the bulkhead pattern adds architectural complexity to the system.
- Increased resource usage – Duplication of resources across components may increase resource consumption.
- Integration challenges – Coordinating and integrating the services can be challenging and introduce potential points of failure.
Use Cases #
Here are some common scenarios where the bulkhead pattern is beneficial:
- Microservices architecture – The bulkhead pattern is used to isolate individual microservices, ensuring fault tolerance and scalability in a distributed system.
- Resource-intensive applications – By partitioning the system into components, the bulkhead pattern optimizes resource allocation, enabling efficient processing of resource-intensive tasks without impacting other components.
- Concurrent processing – The bulkhead pattern helps handle concurrent processing by assigning dedicated resources to each processing unit, preventing failures from affecting other units.
- High-traffic or high-demand systems – In systems experiencing high traffic or demand, the bulkhead pattern distributes the load across components, preventing bottlenecks and enabling scalable handling of increased traffic.
- Modular and extensible systems – The bulkhead pattern facilitates modular development and maintenance, allowing independent updates and deployment of specific components in a system.
Retry Pattern #
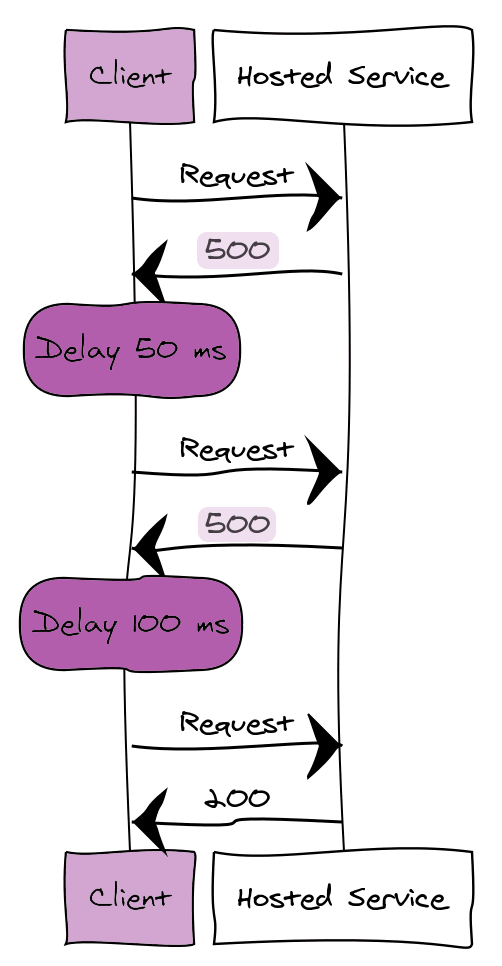
The retry pattern is used to handle temporary failures.
Requests fail for all sorts of reasons, from faulty connections to site reloading after a deployment.
So let’s say we have a client and a service. The client sends a request to the service and receives a response code 500 back.
There are multiple ways to handle this according to the retry pattern.
- If the problem is rare, then retry immediately.
- If the problem is more common, then retry after some amount of delay (for example 50ms, 100ms, etc)
- If the issue is not temporary (invalid credentials, and so on) then cancel the request.
But sometimes, the client thinks that the request has failed #
Sometimes the operation was a success but the request failed to return something. This happens when requests are not stateless, meaning that they change the state of the system somehow (like CRUD operations on a database).
So what we do is we send a duplicate request which can cause problems in the system.
For that, we need some sort of tracking system. We can use the circuit breaker pattern to limit the impact of repeatedly retrying a failed/recovering service.
Pros #
- Resilience and Reliability – By automatically retrying failed requests, you increase the chance of the system recovering from failure (resilience) and increase a chance of a successful requests (reliability).
- Error handling – Retrying an operation transparently hides the error from the end user, making the system appear more robust.
- Simplified Implementation – The retry pattern is simple to implement. Instead of having custom error handling logic for all your requests, you can wrap them all with a
retry pattern class. - Performance optimization – In some cases, temporary errors may be resolved quickly, and the subsequent retries can succeed without significant delays. This can help optimize performance by avoiding unnecessary failures and reducing the impact on the end user.
Cons #
- Increased latency – When retries are attempted, there is an inherent delay introduced in the system. If the retries are frequent or the operations take a long time to complete, the overall latency of the system may increase.
- Risk of infinite loops – Without proper safeguards, retries can potentially lead to infinite loops if the underlying error condition persists.
- Increased network and resource usage – Retrying failed operations can lead to additional network traffic and resource utilization.
- Potential for cascading failures – If the underlying cause of the failure is not resolved, retrying the operation may result in cascading failures throughout the system.
- Difficulty in handling idempotent operations – Retrying stateful requests can lead to unintended consequences if the request is performed multiple times.
Use Cases #
The applicability of the retry pattern depends on the specific requirements and characteristics of the system being developed.
The pattern is most useful for handling temporary errors. But, you must also keep in mind for scenarios involving long delays, stateful requests, or cases where manual intervention is required.
Now, let’s look at some use cases where retrying requests help:
- Network communication – When working with third party services or APIs over a network, all sorts of errors can occur.
- Database operations – Databases also face the same issues due to temporary unavailability, timeouts, or deadlock situations.
- File or resource access – When accessing files, external resources, or dependencies, failures due to locks, permissions, or temporary unavailability can occur.
- Queue processing – Systems that rely on message queues or event-driven architectures may encounter temporary issues like queue congestion, message delivery failures, or service availability fluctuations.
- Distributed transactions – In distributed systems, performing coordinated transactions across multiple services or components can face challenges like network partitions or temporary service failures.
- Data synchronization – When synchronizing data between different systems or databases, temporary errors can disrupt the synchronization process.
Scatter Gather Pattern #
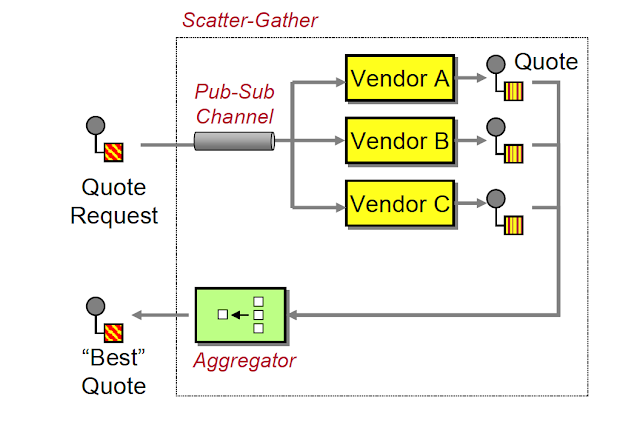
Let’s say we have a process-heavy task like video compression.
We get a video and have to compress it into 5 different resolutions such as 240p, 360p, 480, 720p, and 1080p.
We have a single image compression service that takes in the video and processes each resolution sequentially. The problem here is that it’s very slow.
The scatter-gather pattern advises us to run multiple of these processes simultaneously and gather all the results in one place.
So for our video process examples, this is how it will look:
- Scatter – We will divide the task into multiple nodes, so one node will take care of compressing the video into 240p, another to 360p, and so on.
- Process – Each node will compress its video individually and simultaneously.
- Gather – Once all the nodes have finished compressing the videos, the videos will be stored on some server and we collect the links for all the different versions.
Instead of waiting for each of our videos to be compressed sequentially, now we can parallelize this whole process and increase performance significantly.
Pros #
- Parallel Processing – The scatter-gather pattern improves performance by enables parallel processing of subtasks. Tasks can execute concurrently across multiple nodes or processors.
- Scalability – The scatter gather pattern allows us to scale horizontally, the higher our workload, the more nodes we provision.
- Fault Tolerance – This pattern enhances fault tolerance by redistributing failed subtasks to other available nodes, ensuring the overall task can still be completed successfully.
- Resource Utilization – The scatter-gather pattern optimizes resource utilization by efficiently leveraging available computational resources across multiple nodes or processors.
Cons #
- Communication Overhead – This pattern involves communication between nodes which introduce potential latency and network congestion that may impact overall performance, especially with large data volumes.
- Load Balancing – Balancing the workload evenly across nodes can be challenging, leading to potential inefficiencies and performance bottlenecks if some nodes are idle while others are overloaded.
- Complexity – This pattern is not easy to implement and adds an aditional layer of complexity to the system. It requires careful planning and synchronization mechanisms to coordinate subtasks.
- Data Dependency – Handling dependencies among subtasks, where the output of one subtask is needed as input for another, can be more complex in the scatter-gather pattern compared to other patterns.
Use Cases #
The scatter-gather pattern is useful in distributed systems and parallel computing scenarios where you can divide tasks into smaller subtasks that can be performed concurrently across multiple nodes and processors.
Here are some use cases where the scatter-gather pattern can be used:
- Web Crawling – You can use the scatter gather pattern to fetch and crawl multiple web pages concurrently.
- Data Analytics – Apply scatter-gather to divide large datasets into chunks for parallel processing in data analysis tasks, combining individual results for final insights.
- Image/Video Processing – Utilize scatter-gather for distributed image/video processing, such as encoding frames in parallel and gathering results for the final output.
- Distributed Search – Implement scatter-gather in distributed search systems to distribute search queries across nodes, gather and rank results for final search output.
- Machine Learning – Apply scatter-gather in distributed machine learning for parallel model training on scattered data and combining models for final trained model.
- MapReduce – Incorporate scatter-gather in the MapReduce model for big data processing, scattering input, parallel processing of intermediate results, and gathering for final output.
Bloom Filters (Data Structure) #
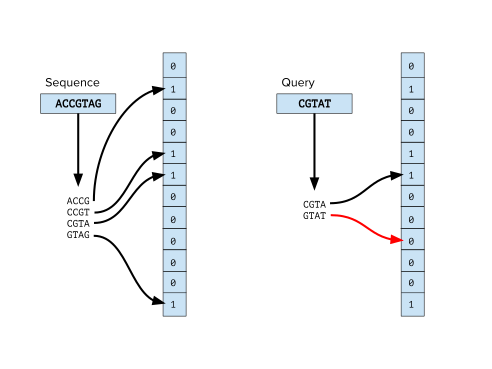
Bloom filters is a data structure that is designed to tell you efficiently both in memory and speed whether an item is in a set.
But the cost of this efficiency is that it is probabilistic. It can tell you that an item is either:
- Definitely not in a set.
- Might be in a set.
Pros #
- Space Efficiency – Bloom filters usually require a smaller amount of memory to store the same number of elements compared to hash tables or other similar data structures.
- Fast Lookups – Checking whether an element is in a Bloom filter has a constant-time complexity regardless of the size of the filter or the number of elements it contains.
- No False Negatives – Bloom filters provide a definitive “no” answer if an element is not in the filter. There are no false negatives, meaning if the filter claims an element is not present, it is guaranteed to be absent.
- Parallelizable – Bloom filters can be easily parallelized, allowing for efficient implementation on multi-core systems or distributed environments.
Cons #
- False Positives – Due to their probabilistic nature, there is a small probability that the filter will incorrectly claim an element is present when it is not. The probability of false positives increases as the filter becomes more crowded or the number of elements increases.
- Limited Operations – Bloom filters only support insertion and membership tests. They do not allow deletion of elements or provide a mechanism to retrieve the original elements stored in the filter. Once an element is inserted, it cannot be removed individually.
- Fixed Size – The size of the bloom filter must be determined beforehand and cannot dynamically resize. If these parameters are not estimated accurately, the filter may become ineffective or waste memory.
- Unordered Data – Bloom filters do not maintain the order or provide any information about the stored elements. They are not suitable for scenarios that require ordering or retrieval of elements based on certain criteria.
Use Cases #
Bloom filters are most useful in situations where approximate membership tests with a low false positive rate are acceptable and where memory efficiency is a priority.
Here are some scenarios where Bloom filters are particularly beneficial:
- Caching Systems – Bloom filters can be used to quickly check if an item is likely to be present in the cache or not. By checking the bloom filter, the system can avoid the costly operation of fetching the item from the cache or underlying storage if it is not likely to be there, thereby improving overall performance.
- Content Delivery Systems – CDNs use bloom filters to handle cache invalidation. Instead of checking each edge server, we use a bloom filter to identify whether the edge server potentially has a specific resource.
- Anti-Spam Systems – Anti-spam systems check emails against common spam databases. Instead of checking against the databases which is expensive, we use bloom filters which are much more efficient.
- Distributed Data Processing – In a distributed data processing framework such as Hadoop or Spark. We use bloom filters to optimize join operations by pre-filtering data and removing unnecessary shuffles.
Conclusion #
You don’t need to be an expert in all of these things – I’m not. And even if you don’t ever directly use or work with some of these concepts, they are still good to know.
Try to implement them in simple projects. It’s a good idea to keep the projects simple enough so you won’t get sidetracked.
Below, I share with you my favorite resources that I used to learn about distributed systems.
Thank you for reading.
Recommended Resources #
- Microservices.io
- Designing Data Intensive Applications
- System Design Interview Prep
- System Design Prime
- Distributed Systems: Principles and Paradigms
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started