Optimize For... Mediocre Brent Ozar Unlimited
Optimize for… Mediocre? - Brent Ozar Unlimited® #
Excerpt #
Some query hints sound too good to be true. And, unfortunately, usually they aren’t quite as magical as they might seem. Frustration with unpredictable execution times People often learn about parameter sniffing when query execution times stop being predictable. Occasionally you’ll hear about a stored procedure taking much longer than normal, but the next time…
Some query hints sound too good to be true. And, unfortunately, usually they aren’t quite as magical as they might seem.
Frustration with unpredictable execution times #
People often learn about parameter sniffing when query execution times stop being predictable. Occasionally you’ll hear about a stored procedure taking much longer than normal, but the next time you look, it might be faster.
One of the causes of this uneven execution is parameter sniffing. Let’s take a look at how it works– and why it can actually be a very good thing!
Let’s start with two simple queries. #
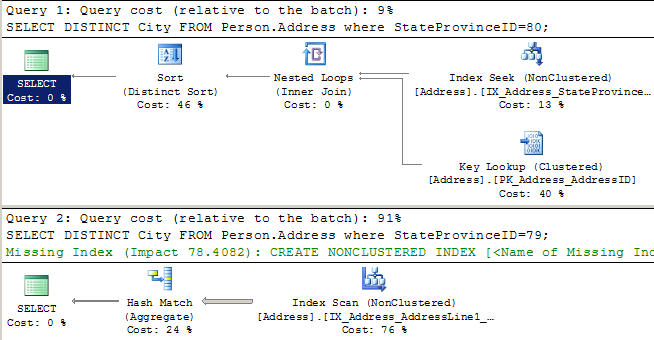
We work at a find company named AdventureWorks. We need to occasionally query a list of distinct cities by State/Province. We get our list by running a simple query– here are two commonly run statements:
SELECT DISTINCT City FROM Person.Address where StateProvinceID=80; SELECT DISTINCT City FROM Person.Address where StateProvinceID=79; |
When we look at the execution plans for these, we can see that SQL Server executes them very differently. For each query, it uses statistics to estimate how many rows it’s going to get back. For the first query it estimates four rows, so it does a little nested loop to pull back the data. For the second query, it estimates it’s going to get 2,636 rows back, so it decides it’s worth it to scan a nonclustered index.
What if we’re using a stored procedure? #
Let’s say we run this query often, and we create a stored procedure to handle our logic. Our stored procedure looks like this:
CREATE PROCEDURE dbo.GetCities @StateProvinceID int AS SELECT DISTINCT City FROM Person.Address WHERE StateProvinceID=@StateProvinceID; GO |
We execute the stored procedure with the same two values as before, and in the exact same order:
EXEC dbo.GetCities @StateProvinceID=80; EXEC dbo.GetCities @StateProvinceID=79; GO |
We’re going to get the same execution plans, right?
Well, no. Instead we get:

Hey, what the heck, SQL Server? When we ran this as simple queries using literal values (no parameters), you realized that one of these got a lot more rows than the other, and you created a special execution plan for each one. Now you’ve decided to use one plan as “one size fits all!”
If we right click on the second execution plan and scroll to the bottom, we can see what happened.
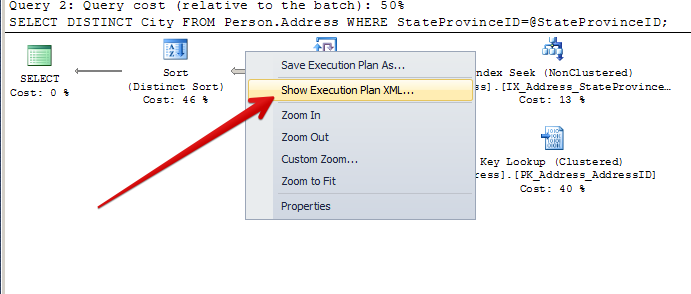
This execution plan was compiled for one value, but was run with another value. The parameter value was “sniffed” during the first run!

This means that the execution plan for this query will vary, depending on what values were used the last time it was compiled. Periodically, recompilation may be triggered by all sorts of things, including changes in data distribution, index changes, SQL Server configuration changes or SQL Server restarts. Whatever parameters are used when the query is first called upon recompilation will heavily influence the shape of the plan.
Enter ‘Optimize for Unknown’ #
Many times, people get frustrated with unpredictable execution times. They hear about a feature that was introduced in SQL Server 2008, and they apply it to solve the problem. The feature is called ‘Optimize for Unknown’. Suddenly, hints are popping up on queries everywhere!
To use the feature, you plug this query hint into your stored procedure like this:
DROP PROCEDURE dbo.GetCities GO CREATE PROCEDURE dbo.GetCities @StateProvinceID int AS SELECT DISTINCT City FROM Person.Address WHERE StateProvinceID=@StateProvinceID OPTION (OPTIMIZE FOR UNKNOWN) GO |
Now, let’s run our queries again:
EXEC dbo.GetCities @StateProvinceID=80; EXEC dbo.GetCities @StateProvinceID=79; GO |
Did we get great execution plans? Well, maybe not:
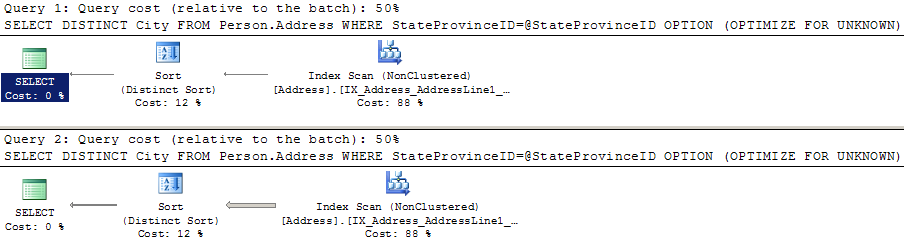
Maybe this is a decent plan for some values, but maybe it isn’t. The query that wanted the “small” nested loop plan did 216 reads in scanning a nonclustered index instead of the 10 it did when it had its ideal plan. If this was a query that ran really frequently, we might not want this plan, either. (Particularly if we had a much larger table).
‘Optimize for Unknown’ has blinders on #
The ‘Optimize for Unknown’ feature follows the premise that trying to get a consistent execution time for a given set of parameters and re-using a stable execution plan is better than spending CPU to compile a special, unique flower of an execution plan every time a query runs. That is sometimes the case. But you should also know that it produces a pretty mediocre plan.
Let’s take a closer look at what it did.
For query 1, it estimated it was going to return 265 rows, when it actually returned 4:
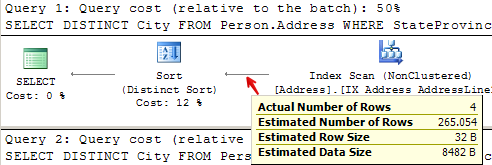
For query 2, it estimated that it was going to return 265 rows, when it actually returned 2,636:
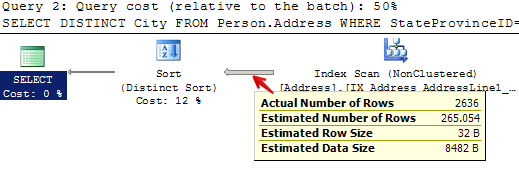
In both cases, it didn’t look at the value for @StateProvinceID that was passed in at all. It pretended it was unknown– just like we told it to. This means that when the plan was created, it didn’t customize it for the values as they were passed in for that execution.
Instead, SQL Server checked out the table and realized that we have an index on the StateProvinceID column. That index has associated statistics. It looked at the statistics to get a measure of how the values are distributed in the index– this is called the “density vector” — read more about it here in a great post by Benjamin Nevarez. It then multipled the “density vector” by the number of rows in the table to create a generic estimate of how many rows might be returned for any sort of “average” value that was used to query the table.
Check it out– we can peek at the statistics header and the density vector:

The density vector for StateProvinceID is in the second result set, first row under “All density”– it’s 0.01351351. Multiply 0.01351351 * 19614 (the number of rows) and you get 265.05398514. And so the plan was created based on an “average” or “mediocre” estimate of 265 rows– which was very different than either of the queries we ran.
Well, just how bad is a mediocre plan? #
In this case, this isn’t terrible. I’m just running a few test queries against a small database.
But in this case you could say the same thing about parameter sniffing. The plans I got there weren’t terrible, either! In both cases SQL Server was able to re-use execution plans without creating a freshly compiled plan for each run. That’s good because CPU is expensive: I don’t want to compile all the time.
But in a larger, more complex plan, ‘optimize for unknown’ may make execution times more consistent, but it may also produce a very inefficient plan. The “blind” style of estimate may not match ANY real values well, depending on how my data is distributed. I may end up with a plan which thinks it’s dealing with way more or less data than it’s actually handling. Both of these can present real problems with execution.
So what’s the ideal fix? #
I’ve got good news and I’ve got bad news.
The bad news is that there is no single setting that will always produce the perfect exection plan without possibly having extreme adverse impacts on your performance. I can’t tell you “Just do X and it’ll always be fine.”
Instead, you should let parameter sniffing happen most of the time. It’s not a bug, it’s a feature. (Really!) Don’t default to using any query hints– just stay simple and let the optimizer figure it out.
You will have times that you find stored procedures and other parameterized queries (called by sp_executesql or queries using sp_prepare) have uneven execution times. In those cases, you need to figure out how often they’re executing and if there’s a single plan that helps them the most. You may solve the problem with an ‘Optimize for Unknown’ hint, or you may use another hint. No matter what you do, you’ll be making a trade-off between performance gains and possible different performance pains. Cross each bridge when you come to it.
What was the good news? #
The bright side is that fixing these issues are fun! How queries are optimized and executed against different sets of data is super interesting to dive into. These little things mean that we’ll always need people to help make applications faster– and a little job security never hurt anyone.
Learn More in Our Execution Plan Training #
Our How to Read Execution Plans Training explains how to get an execution plan, how to read the operators, and learn solutions to common query problems.